Azure SQL Data Synchronisation Process
Read-only replicas of an Azure SQL Database database with Active geo-replication are easy to setup but there are some disadvantages. e.g. bi-directional synchronisation is not supported, not all tables or selected columns of some tables might not be needed\should not be accessible for reporting, the overhead of replicating tables used for transaction processing might impact on the performance of the solution etc. Azure SQL Data Sync is a service built on Azure SQL Database that can synchronise selected data bi-directionally across multiple databases, both on-premises and in the cloud.
The first step was to remove all the Microsoft SQL Server features used in the the World Wide Importers database (e.g. Sequence Numbers, Column Store indexes etc.) which are not supported(see general limitiations) by Azure SQL Data Sync. I then used the “Deploy Database Wizard” to copy my modified World Wide Importers database to an Azure SQL Database.


For my “read-only replicas” scenario if there are any update conflicts the the source database “wins”.









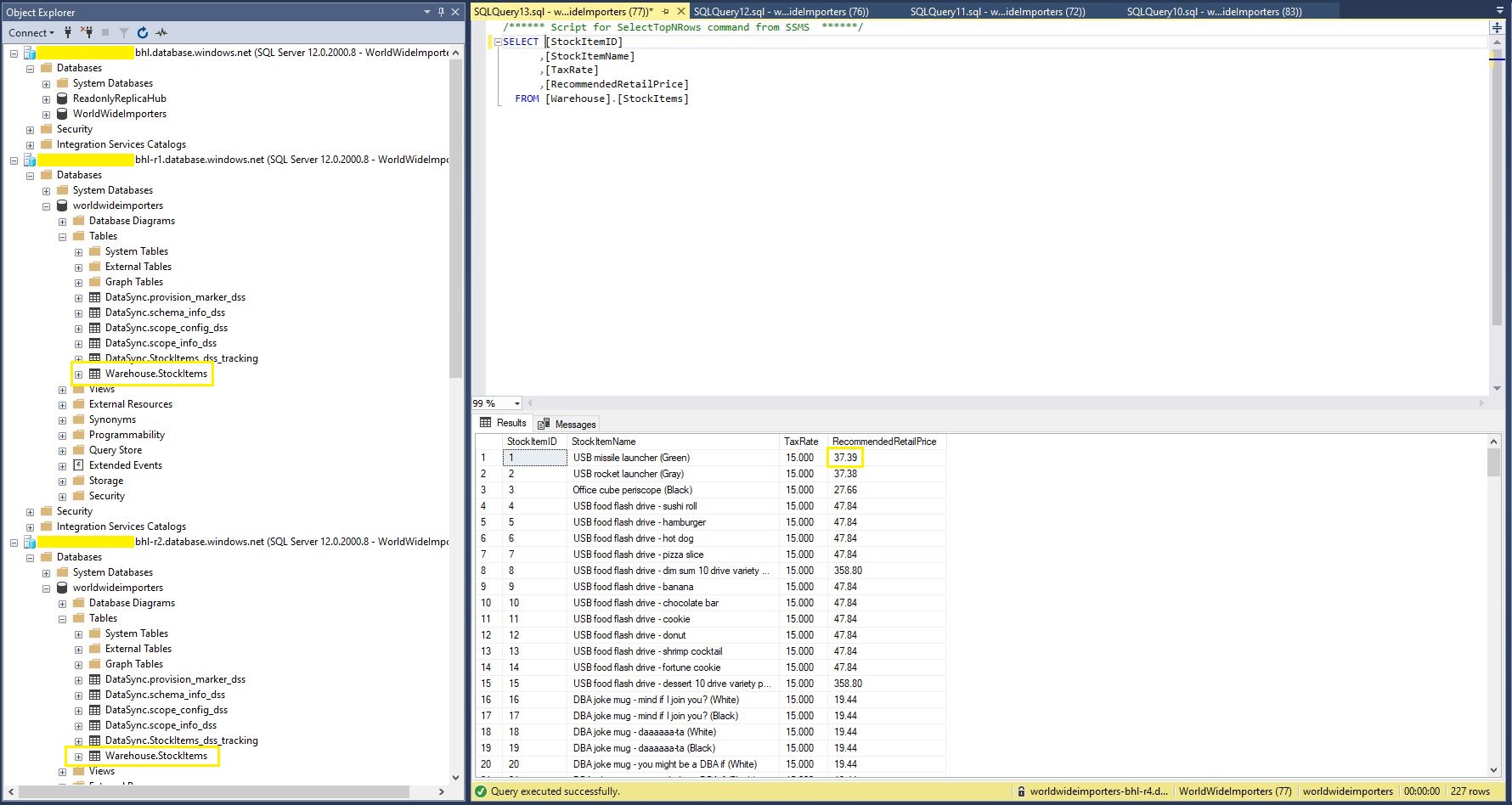
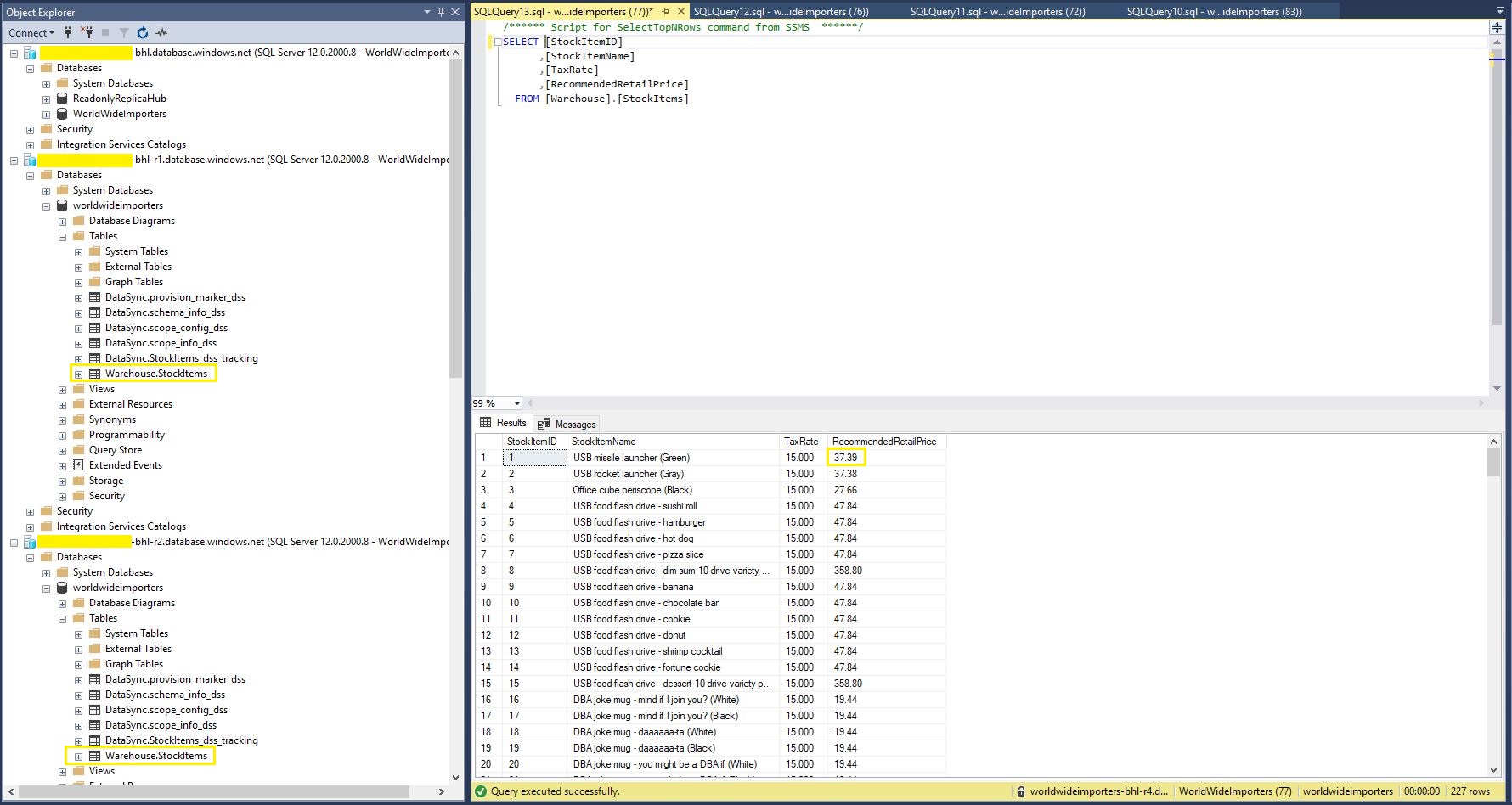
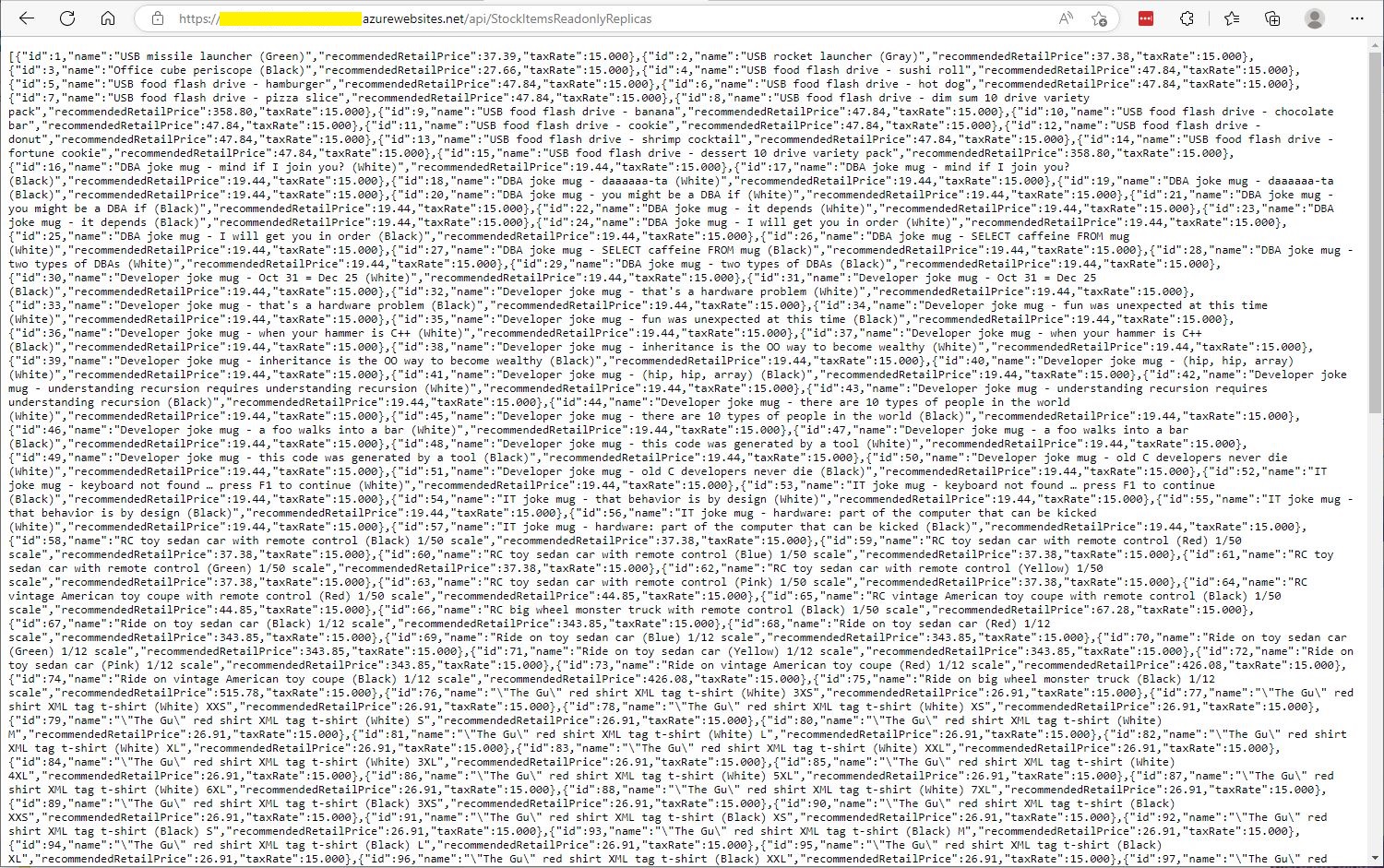
The Azure SQL Database Data Sync was pretty easy to setup (configuration in the hub database tripped me up initially). For a production scenario where only a portion of the database (e.g. shaped by Customer, Geography, security considerations, or a bi-directional requirement) it would be an effective solution, though for some applications the delay between synchronisations might be an issue.
