To see how the dme-compunet, updated YoloDotNet and sstainba NuGets performed on an ARM64 CPU I built a test rig for the different NuGets using standard images and ONNX Models.

I started with the dme-compunet YoloV8 NuGet which found all the tennis balls and the results were consistent with earlier tests.

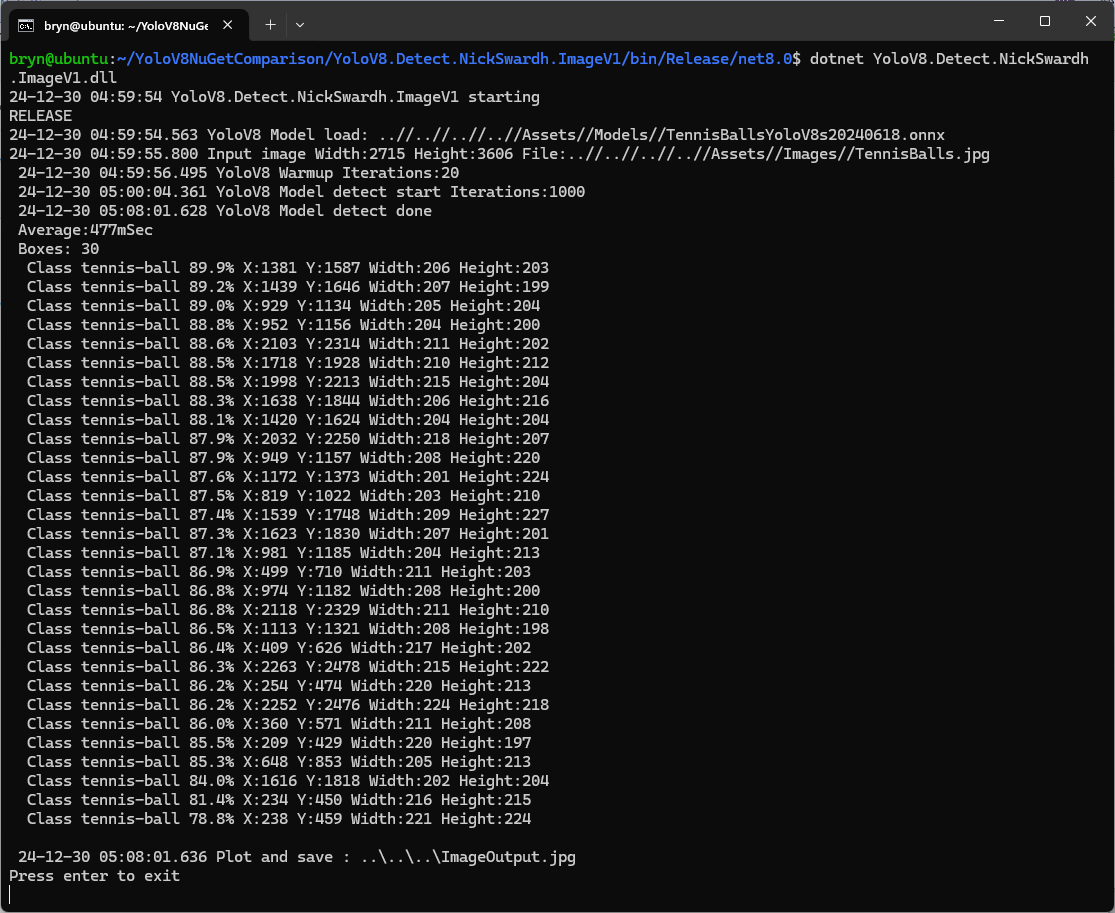
The YoloDotNet by NickSwardh NuGet update had some “breaking changes” so I built “old” and “updated” test harnesses.
The YoloDotNet by NickSwardh V1 and V2 results were slightly different. The V2 NuGet uses SkiaSharp which appears to significantly improve the performance.

Even though the YoloV8 by sstainba NuGet hadn’t been updated I ran the test harness just in case

The dme-compunet YoloV8 and NickSwardh YoloDotNet V1 versions produced the same results, but the NickSwardh YoloDotNet V2 results were slightly different.
- dme-Compunet 291 mSec
- NickSwardV1 480 mSec
- NickSwardV2 115 mSecs
- SStainba 422 mSec
Like in the YoloV8-NuGet Performance X64 CPU post the NickSwardV2 implementation which uses SkiaSharp was significantly faster so it looks like Sixlabors.ImageSharp is the issue.
To support Compute Unified Device Architecture (CUDA) or TensorRT inferencing with NickSwardV2(for SkiaSharp) will need some major modifications to the code so it might be better to build my own YoloV8 Nuget.

{kind=link}
How did you get this working on WSL / arm64? There are no linux ARM64 native assets for YoloDotnet on nuget as far as I can see. Did you build them yourself?
Hi
YoloDotNet is a .NET framework + SkiaSharp so should work on any platform with a .NET runtime + SkiaSharp support.
After shaping the image (scale/pillarbox/letterbox) to correct format for model and loading the Tensor. I used the ARM64 native ML.NET framework libraries (they are in folders under the X64 bits) to do the inferencing.
More recently I have been using the SkiaSharp, which is a wrapper around native libraries for different platforms and my own Tensor packing and unpacking code which I have been tuning with BenchMark.net
A while back I built the ARM64+Jetson CUDA & TensorRT ONNX execution providers which massively speeds up inferencing.
These days I use my own lightweight wrappers which only do object detection/classification (will do segmentation/keypoints at some stage) for Yolo26 so I don’t have todo NMS and other post processing.
Bryn