This is the first in a series of posts from my session at the Agent Camp – Christchurch about using Open Neural Network Exchange(ONNX) for processing Moving Picture Experts Group (MPEG) video and Pulse Code Modulation(PCM) audio streams.
For processing video streams one of the first steps is extracting individual Joint Photographic Experts Group(JPEG) images from MPEG Real-Time Streaming Protocol(RTSP) stream. The jpeg images then have to transformed into an ONNX DenseTensor<float> in the correct format for the Ultralytics Yolo26 model. These image processing posts will use Ultralytics Yolo26 standard Small object detection model which has an input image size of 640*640pixels.
I have used both the YoloSharp and YoloDotNet libraries (Thank you Niklas Swärd and dme-compunet I appreciate the amount of effort you have put in). Both these libraries have support for object detection, instance segmentation, oriented bounding boxes detection(OBB), classification and pose estimation. They both have support for different versions, video stream processing, plotting minimum bounding boxes, Non-Maximum Suppression(NMS) for earlier models like YOLOv8 or YOLO11. I just need object detection (none of the other model types, plotting minimum boxes etc.) to work as fast as possible on my Seeedstudio EdgeBox RPi 200.
First step, was to use Benchmark.Net compare the performance of Six Labors ImageSharp (used by YoloSharp) and SkiaSharp (used by YoloDotNet). Six Labors ImageSharp is a high-performance, fully managed, 2D graphics API whereas SkiaSharp is a wrapper for Google’s Skia 2D Graphics Library.
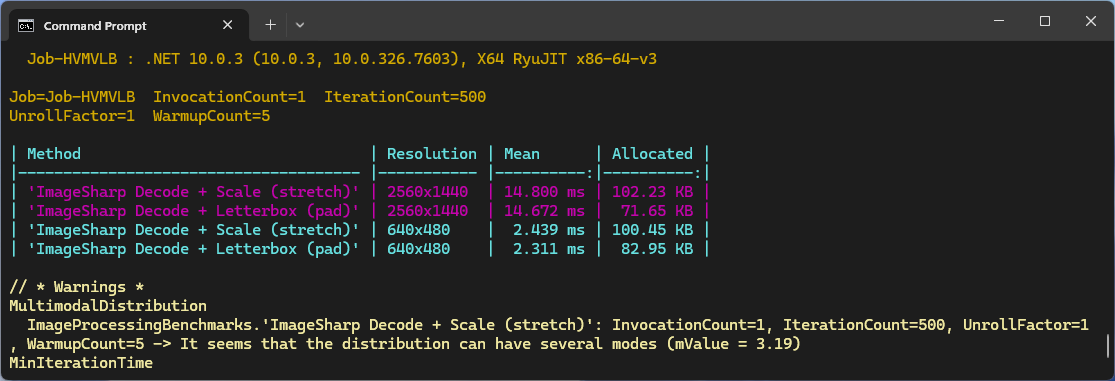
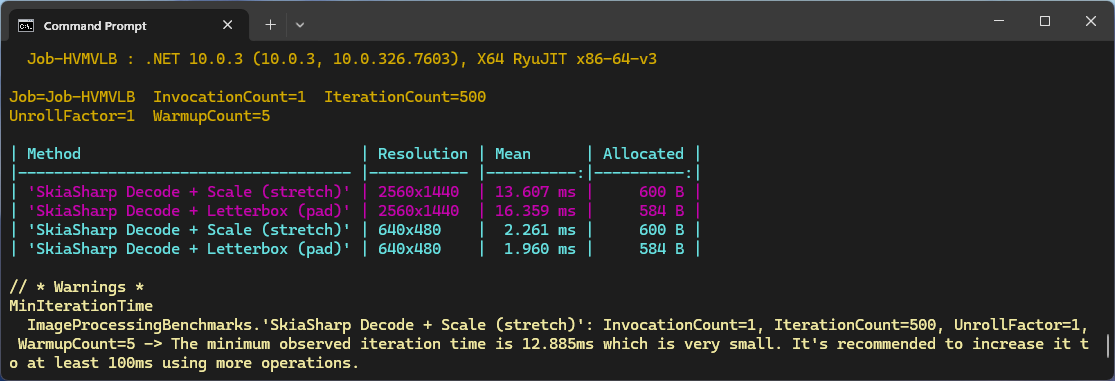
The initial comparison running on my development box (will benchmark on my Seeedstudio EdgeBox RPi 200.) was roughly what I was expecting though the SkaiSharp 2560×1440 mean duration was a bit odd. I think that the difference in the amount of memory allocated is because SkaiSharp’s memory is allocated by the native code. Both benchmarks need some refactoring to improve repeatability on my different platforms.
These benchmarks should be treated as indicative not authoritative







{kind=link}