Random wanderings through Microsoft Azure esp. PaaS plumbing, the IoT bits, AI on Micro controllers, AI on Edge Devices, .NET nanoFramework, .NET Core on *nix and ML.NET+ONNX
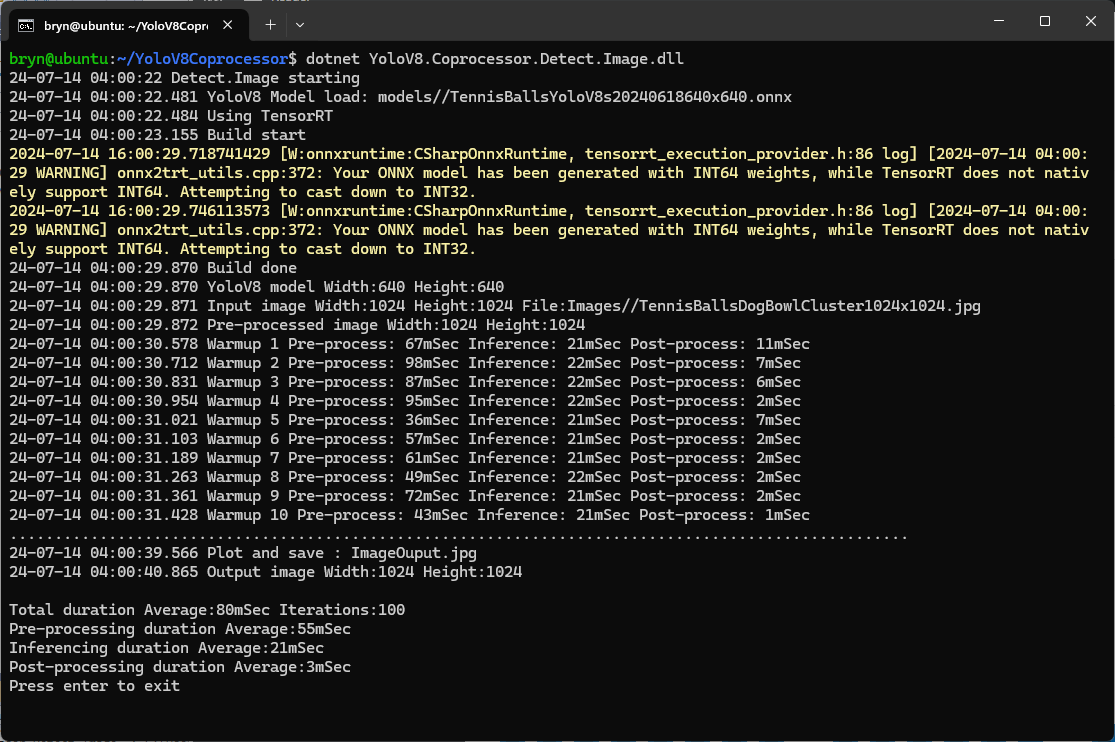
Enabling CUDA reduced the total image scaling, pre-processing, inferencing, and post processing time from 115mSec to 36mSec which is a significant improvement.
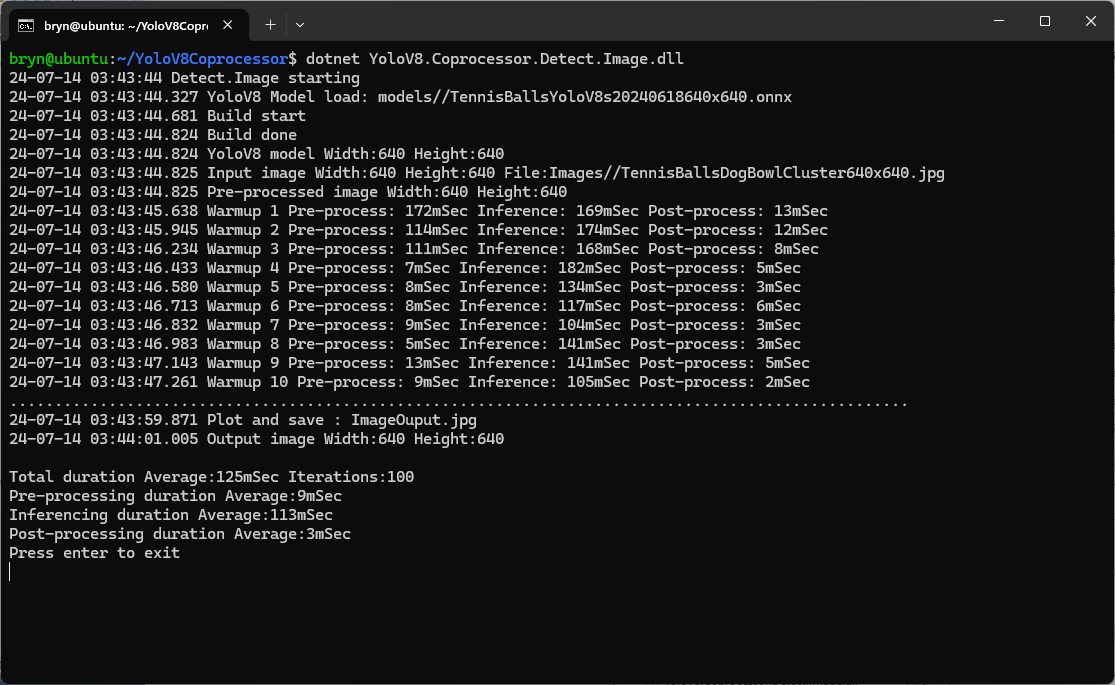
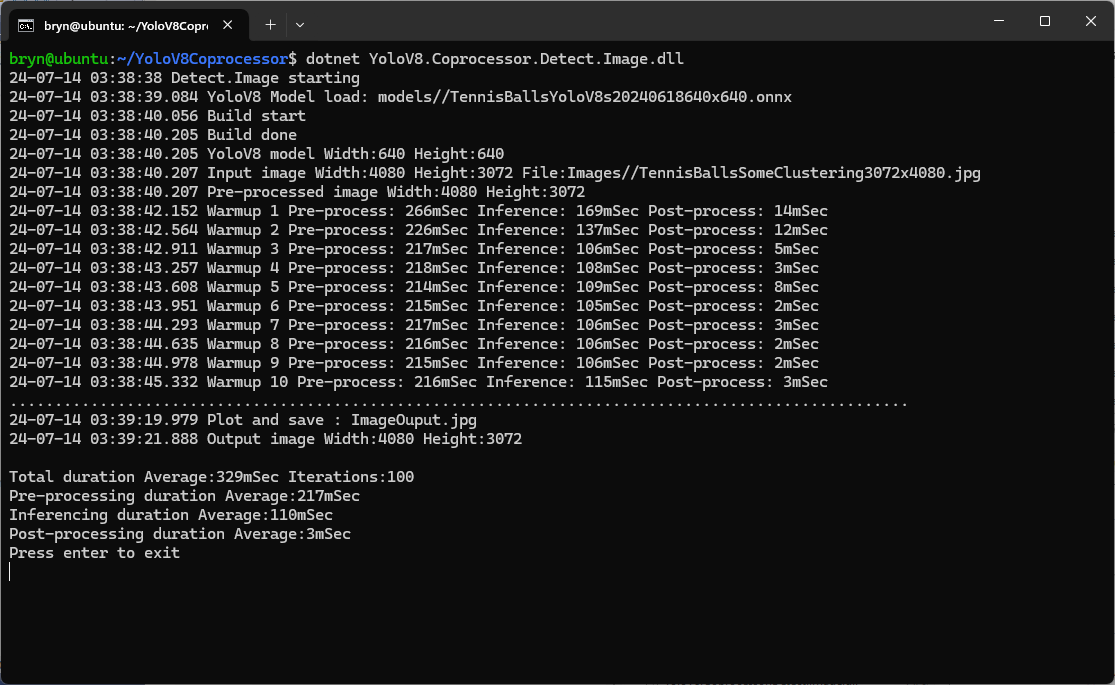
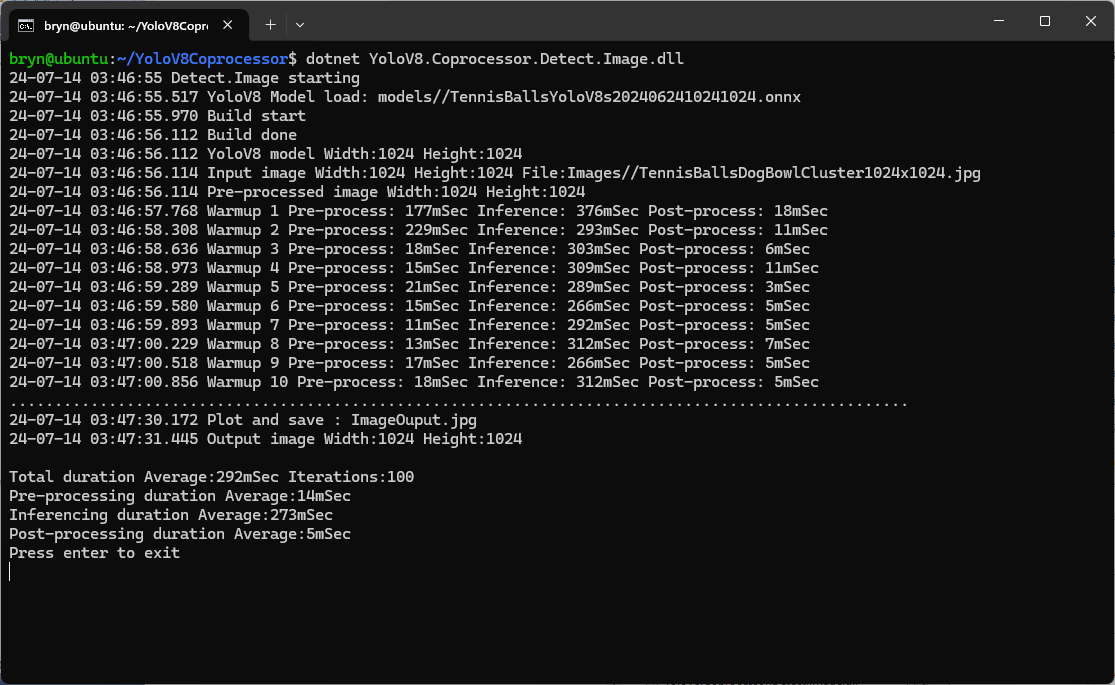
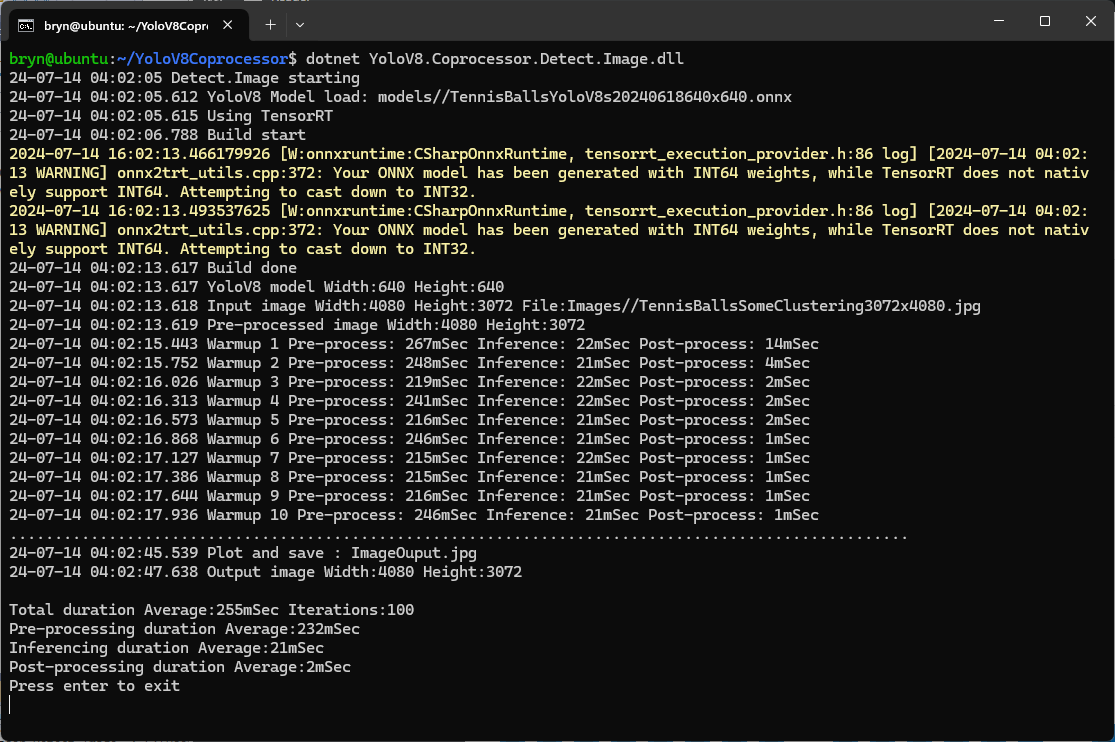
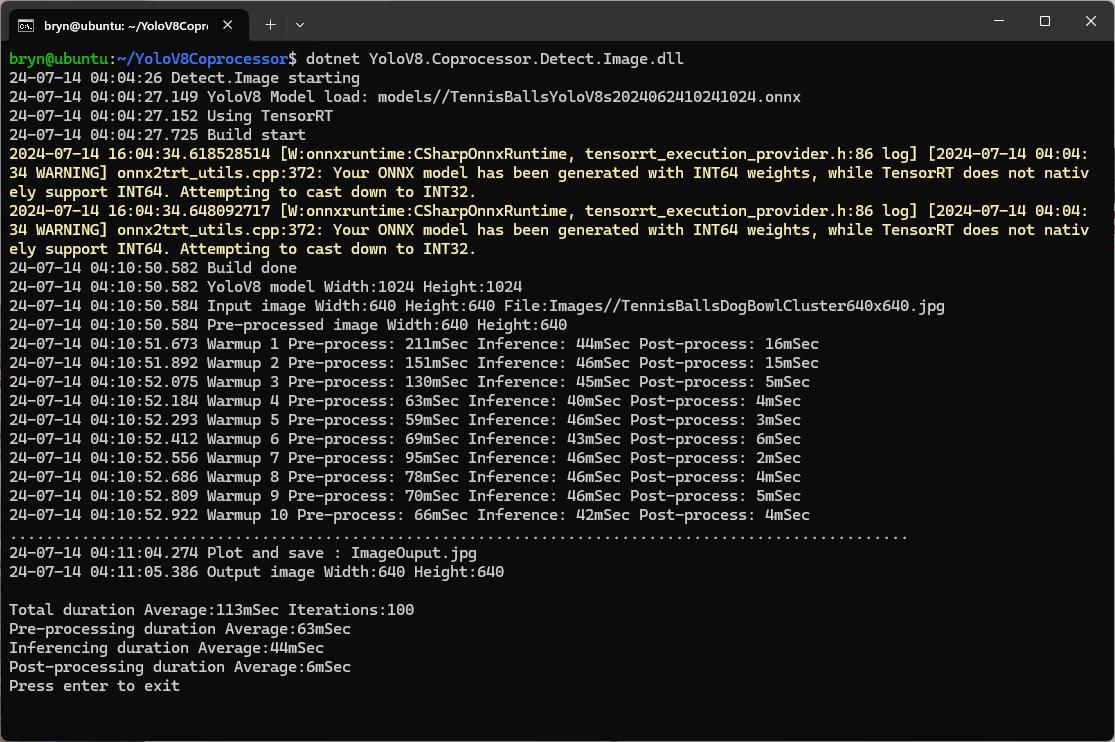
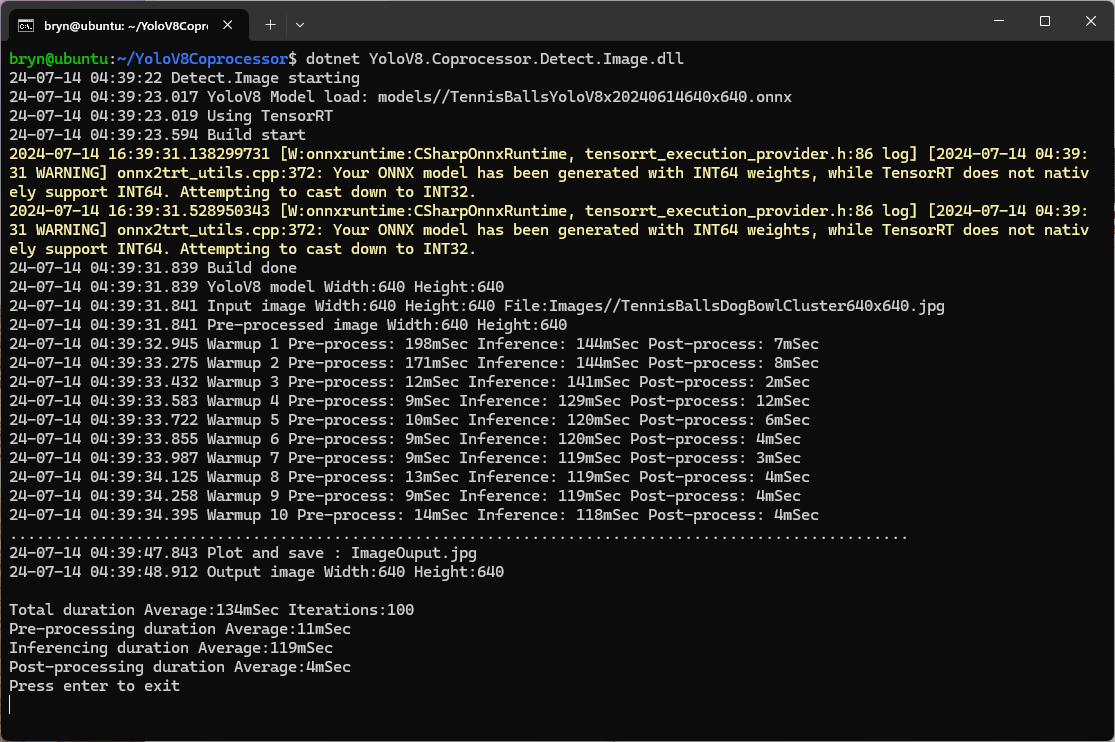
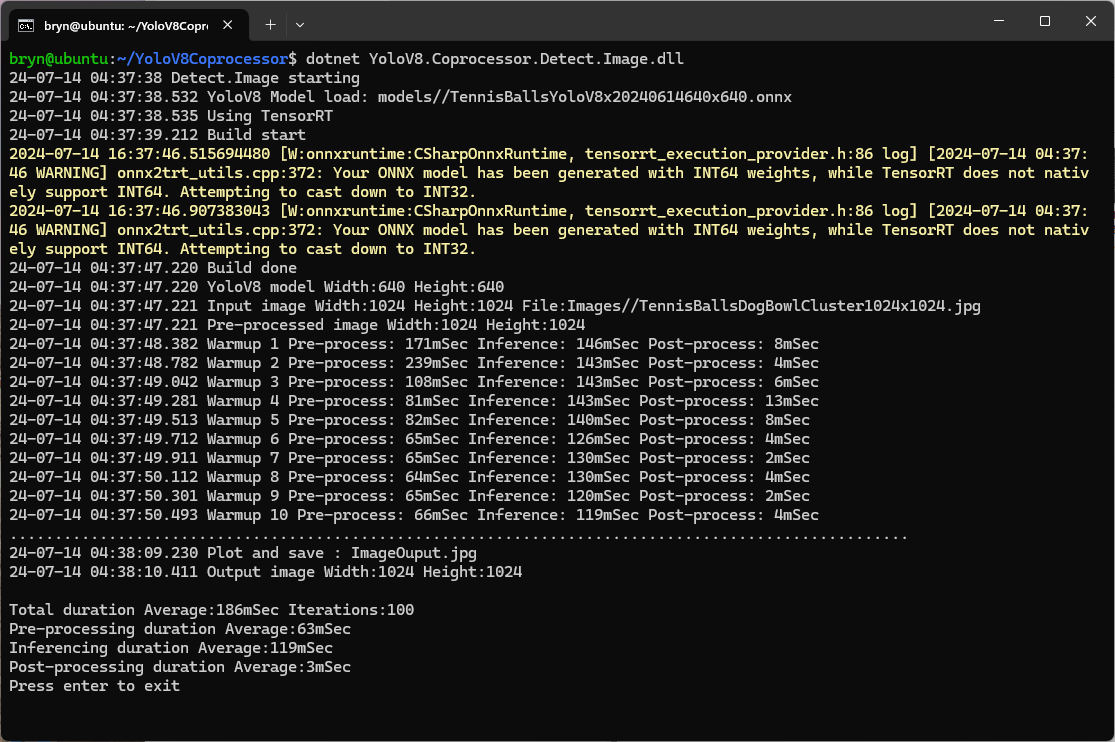
The testing consisted of permutations of three models TennisBallsYoloV8s20240618640×640.onnx, TennisBallsYoloV8s2024062410241024.onnx & TennisBallsYoloV8x20240614640×640 (limited testing as slow) and three images TennisBallsLandscape640x640.jpg, TennisBallsLandscape1024x1024.jpg & TennisBallsLandscape3072x4080.jpg.
Executive Summary
As expected, inferencing with a TensorRT 640×640 model and a 640×640 image was fastest, 9mSec pre-processing, 21mSec inferencing, then 4mSec post-processing.
If the image had to be scaled with SixLabors.ImageSharp this significantly increased the preprocessing (and overall) time.
Generating the TensorRT engine every time the application is started
The TensorRT Execution provider has a number of configuration options but the IYoloV8Builder interface had to modified with UseCuda, UseRocm, UseTensorrt and UseTvm overloads implemented to allow additional configuration settings.
...
public class YoloV8Builder : IYoloV8Builder
{
...
public IYoloV8Builder UseOnnxModel(BinarySelector model)
{
_model = model;
return this;
}
#if GPURELEASE
public IYoloV8Builder UseCuda(int deviceId) => WithSessionOptions(SessionOptions.MakeSessionOptionWithCudaProvider(deviceId));
public IYoloV8Builder UseCuda(OrtCUDAProviderOptions options) => WithSessionOptions(SessionOptions.MakeSessionOptionWithCudaProvider(options));
public IYoloV8Builder UseRocm(int deviceId) => WithSessionOptions(SessionOptions.MakeSessionOptionWithRocmProvider(deviceId));
// Couldn't test this don't have suitable hardware
public IYoloV8Builder UseRocm(OrtROCMProviderOptions options) => WithSessionOptions(SessionOptions.MakeSessionOptionWithRocmProvider(options));
public IYoloV8Builder UseTensorrt(int deviceId) => WithSessionOptions(SessionOptions.MakeSessionOptionWithTensorrtProvider(deviceId));
public IYoloV8Builder UseTensorrt(OrtTensorRTProviderOptions options) => WithSessionOptions(SessionOptions.MakeSessionOptionWithTensorrtProvider(options));
// Couldn't test this don't have suitable hardware
public IYoloV8Builder UseTvm(string settings = "") => WithSessionOptions(SessionOptions.MakeSessionOptionWithTvmProvider(settings));
#endif
...
}
...
YoloV8Builder builder = new YoloV8Builder();
builder.UseOnnxModel(_applicationSettings.ModelPath);
if (_applicationSettings.UseTensorrt)
{
Console.WriteLine($" {DateTime.UtcNow:yy-MM-dd HH:mm:ss.fff} Using TensorRT");
OrtTensorRTProviderOptions tensorRToptions = new OrtTensorRTProviderOptions();
Dictionary<string, string> optionKeyValuePairs = new Dictionary<string, string>();
optionKeyValuePairs.Add("trt_engine_cache_enable", "1");
optionKeyValuePairs.Add("trt_engine_cache_path", "enginecache/");
tensorRToptions.UpdateOptions(optionKeyValuePairs);
builder.UseTensorrt(tensorRToptions);
}
...
In order to validate that the loaded engine loaded from the trt_engine_cache_path is usable for the current inference, an engine profile is also cached and loaded along with engine
If current input shapes are in the range of the engine profile, the loaded engine can be safely used. If input shapes are out of range, the profile will be updated and the engine will be recreated based on the new profile.
Reusing the TensorRT engine built the first time the application is started
When the YoloV8.Coprocessor.Detect.Image application was configured to use NVIDIA TensorRT and the engine was cached the average inference time was 58mSec and the Build method took roughly 10sec to execute after the application had been run once.