While working on my RTSPCameraNagerVideoStream project I noticed that after opening the Realtime Streaming Protocol(RTSP) connection with my HiLook IPCT250H Security Camera it took a while for the application to start writing image files.
My test harness code was “inspired” by the Nager.VideoStream.TestConsole application with a slightly different file format for the start-stop marker text and camera images files.
private static async Task StartStreamProcessingAsync(InputSource inputSource, CancellationToken cancellationToken = default)
{
Console.WriteLine("Start Stream Processing");
try
{
var client = new VideoStreamClient();
client.NewImageReceived += NewImageReceived;
#if FFMPEG_INFO_DISPLAY
client.FFmpegInfoReceived += FFmpegInfoReceived;
#endif
File.WriteAllText(Path.Combine(_applicationSettings.ImageFilepathLocal, $"{DateTime.UtcNow:yyyyMMdd-HHmmss.fff}.txt"), "Start");
await client.StartFrameReaderAsync(inputSource, OutputImageFormat.Png, cancellationToken: cancellationToken);
File.WriteAllText(Path.Combine(_applicationSettings.ImageFilepathLocal, $"{DateTime.UtcNow:yyyyMMdd-HHmmss.fff}.txt"), "Finish");
client.NewImageReceived -= NewImageReceived;
#if FFMPEG_INFO_DISPLAY
client.FFmpegInfoReceived -= FFmpegInfoReceived;
#endif
Console.WriteLine("End Stream Processing");
}
catch (Exception exception)
{
Console.WriteLine($"{exception}");
}
}
private static void NewImageReceived(byte[] imageData)
{
Debug.WriteLine($"{DateTime.UtcNow:yy-MM-dd HH:mm:ss.fff} NewImageReceived");
File.WriteAllBytes( Path.Combine(_applicationSettings.ImageFilepathLocal, $"{DateTime.UtcNow:yyyyMMdd-HHmmss.fff}.png"), imageData);
}
I used Path.Combine so no code or configuration changes were required when the application was run on different operating systems (still need to ensure ImageFilepathLocal in the appsettings.json is the correct format).
Developer Desktop
I used my desktop computer a 13th Gen Intel(R) Core(TM) i7-13700 2.10 GHz with 32.0 GB running Windows 11 Pro 24H2.
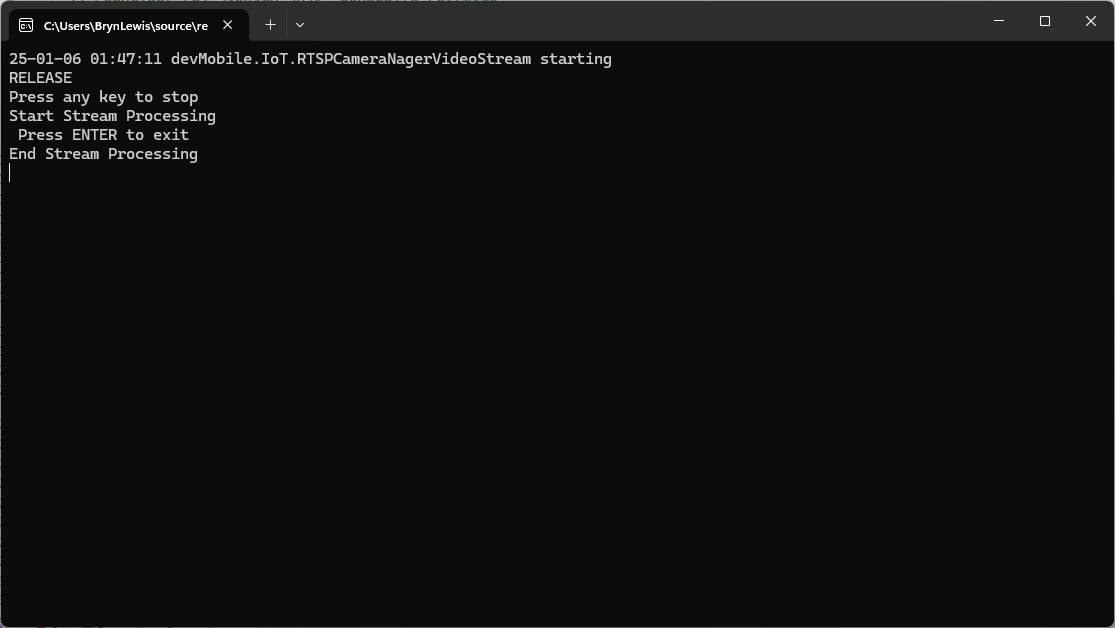
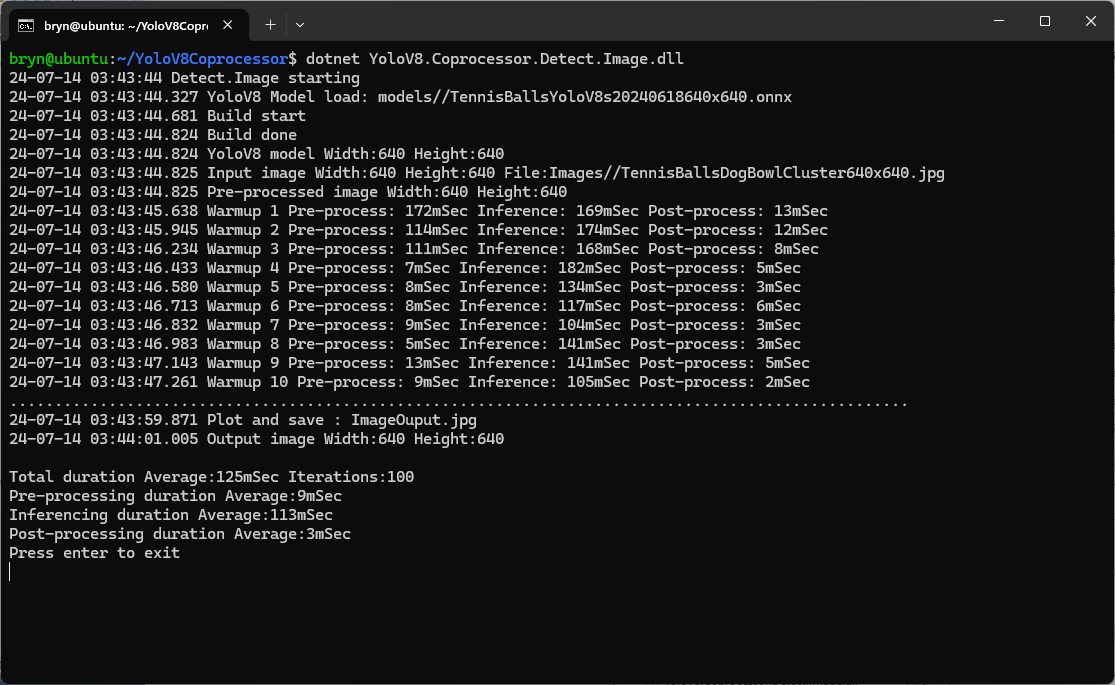
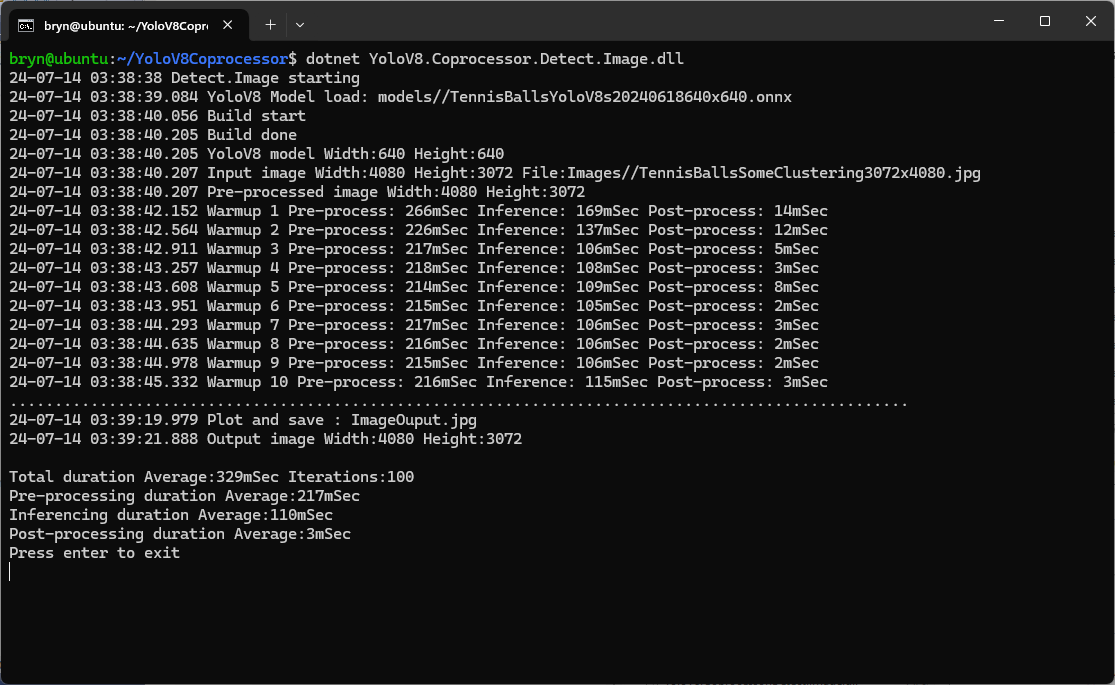
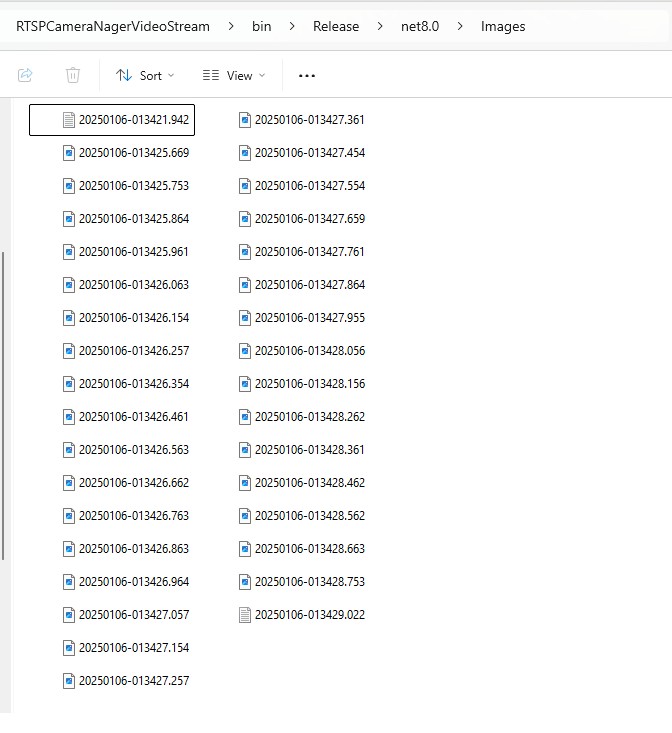
In the test results below (representative of multiple runs while testing) the delay between starting streaming and the first image file was on average 3.7 seconds with the gap between the images roughly 100mSec.
Industrial Computer
I used a reComputer J3011 – Edge AI Computer with NVIDIA® Jetson™ Orin™ Nano 8GB running Ubuntu 22.04.5 LTS (Jammy Jellyfish)
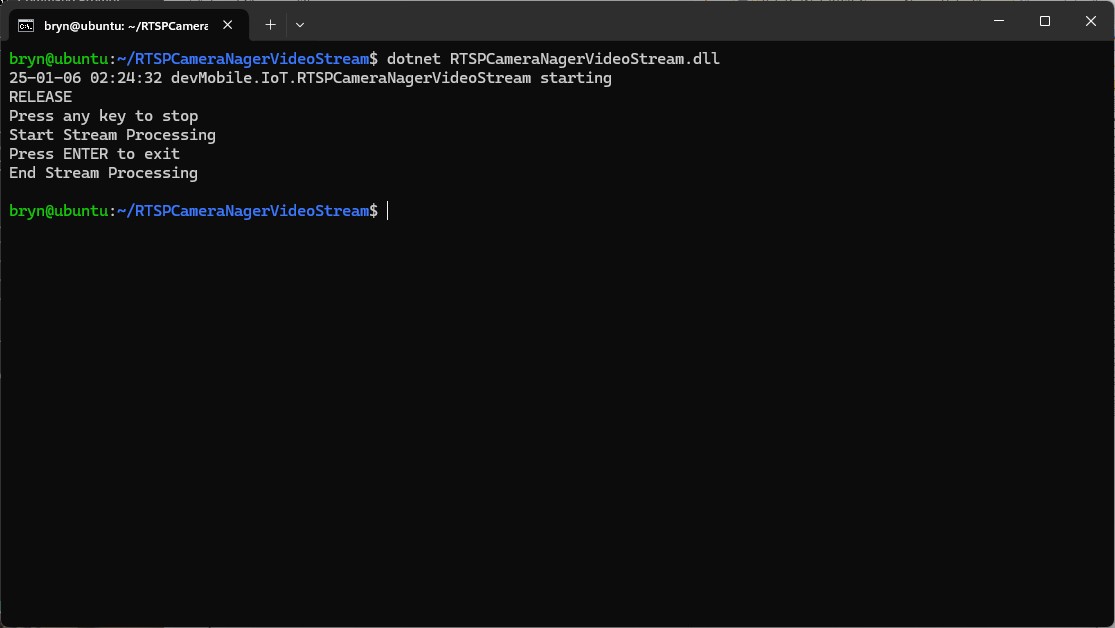
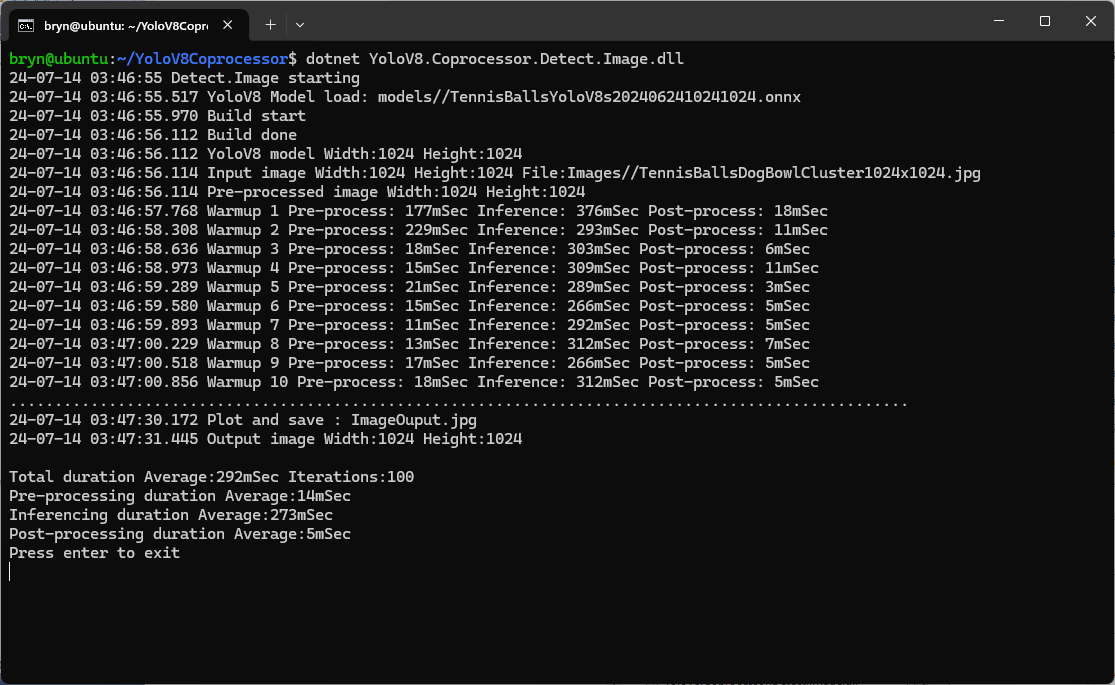
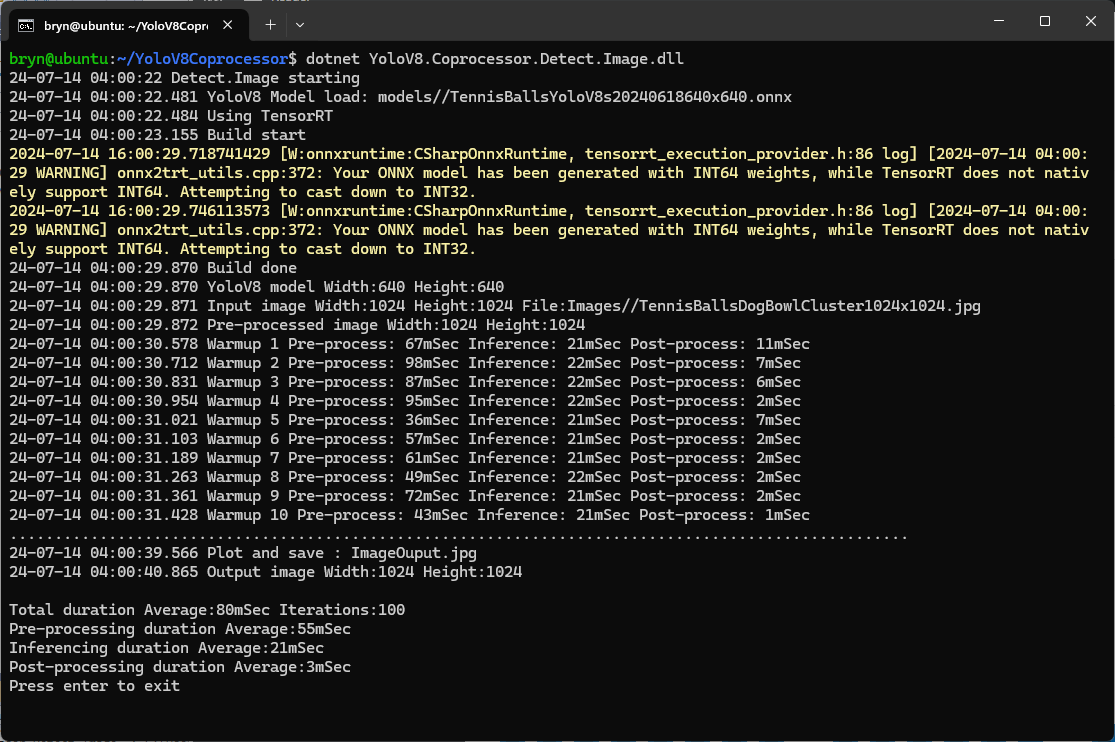
In the test results below (representative of multiple runs while testing) the delay between starting streaming and the first image file was on average roughly 3.7 seconds but the time between images varied a lot from 30mSec to >300mSec.
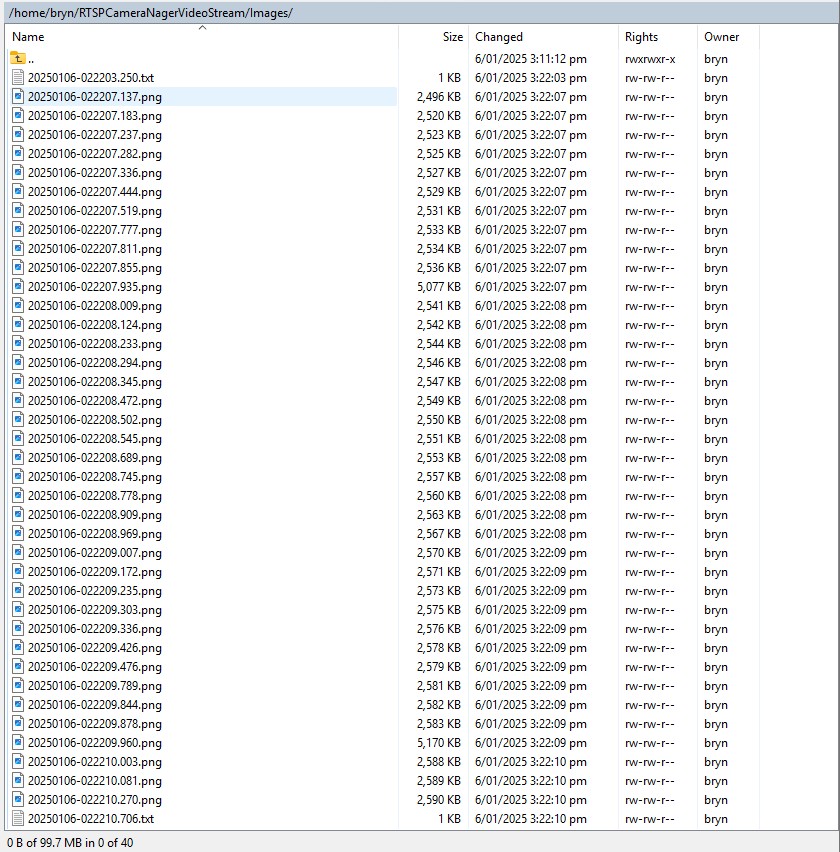
At 10FPS the results for my developer desktop were more consistent, and the reComputer J3011 had significantly more “jitter”. Both could cope with 1oFPS so the next step is to integrate YoloDotNet library to process the video frames.