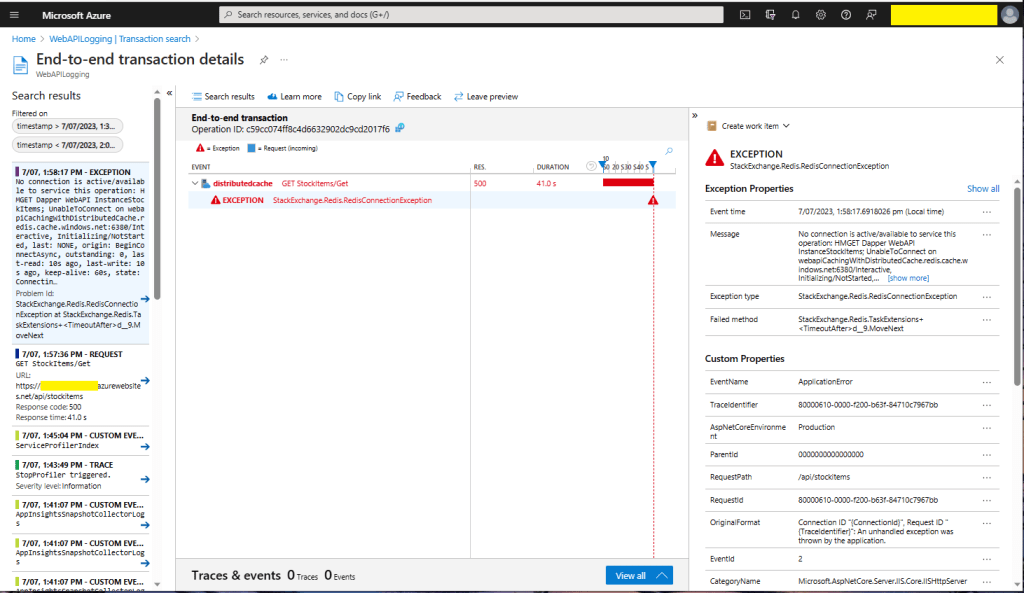
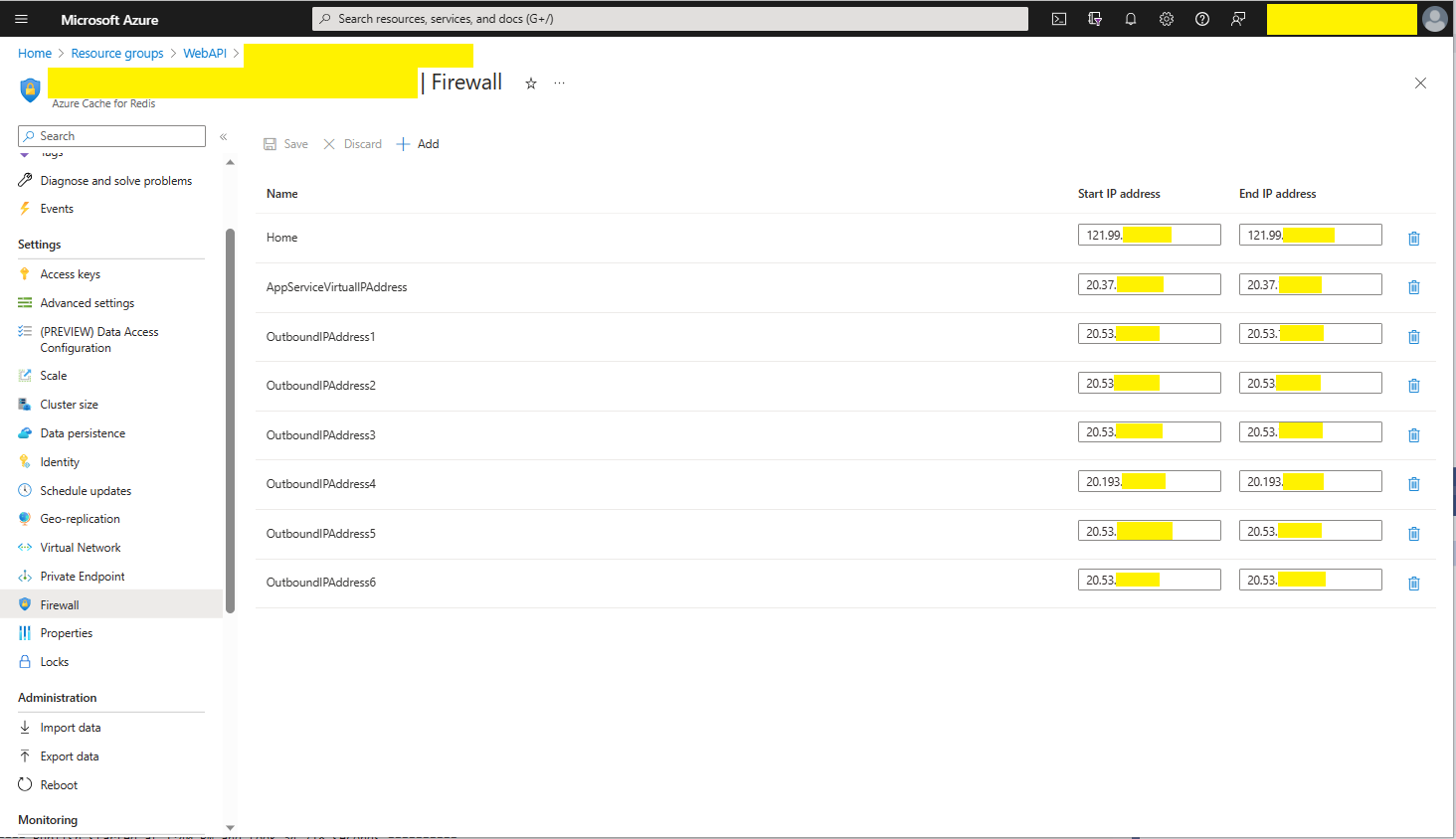
The IDistributedCache has Memory, SQL Server and Redis implementations so I wanted to explore how the Stack Exchange Redis library works. The ConnectionMultiplexer class in the Stack Exchange Redis library hides the details of managing connections to multiple Redis servers, connection timeouts etc. The object is fairly “chunky” so it should be initialized once and reused for the lifetime of the program.
public static void Main(string[] args)
{
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
builder.Services.AddApplicationInsightsTelemetry();
// Add services to the container.
builder.Services.AddTransient<IDapperContext>(s => new DapperContext(builder.Configuration));
builder.Services.AddControllers();
builder.Services.AddSingleton<IConnectionMultiplexer>(s => ConnectionMultiplexer.Connect(builder.Configuration.GetConnectionString("Redis")));
var app = builder.Build();
// Configure the HTTP request pipeline.
app.UseHttpsRedirection();
app.MapControllers();
app.Run();
}
I trialed the initial versions of my Redis project with Memurai on my development machine, then configured an Azure Cache for Redis. I then load tested the project with several Azure AppService client and there was a significant improvement in response time.
[ApiController]
[Route("api/[controller]")]
public class StockItemsController : ControllerBase
{
private const int StockItemSearchMaximumRowsToReturn = 15;
private readonly TimeSpan StockItemListExpiration = new TimeSpan(0, 5, 0);
private const string sqlCommandText = @"SELECT [StockItemID] as ""ID"", [StockItemName] as ""Name"", [RecommendedRetailPrice], [TaxRate] FROM [Warehouse].[StockItems]";
//private const string sqlCommandText = @"SELECT [StockItemID] as ""ID"", [StockItemName] as ""Name"", [RecommendedRetailPrice], [TaxRate] FROM [Warehouse].[StockItems]; WAITFOR DELAY '00:00:02'";
private readonly ILogger<StockItemsController> logger;
private readonly IDbConnection dbConnection;
private readonly IDatabase redisCache;
public StockItemsController(ILogger<StockItemsController> logger, IDapperContext dapperContext, IConnectionMultiplexer connectionMultiplexer)
{
this.logger = logger;
this.dbConnection = dapperContext.ConnectionCreate();
this.redisCache = connectionMultiplexer.GetDatabase();
}
[HttpGet]
public async Task<ActionResult<IEnumerable<Model.StockItemListDtoV1>>> Get()
{
var cached = await redisCache.StringGetAsync("StockItems");
if (cached.HasValue)
{
return Content(cached, "application/json");
}
var stockItems = await dbConnection.QueryWithRetryAsync<Model.StockItemListDtoV1>(sql: sqlCommandText, commandType: CommandType.Text);
#if SERIALISER_SOURCE_GENERATION
string json = JsonSerializer.Serialize(stockItems, typeof(List<Model.StockItemListDtoV1>), Model.StockItemListDtoV1GenerationContext.Default);
#else
string json = JsonSerializer.Serialize(stockItems);
#endif
await redisCache.StringSetAsync("StockItems", json, expiry: StockItemListExpiration);
return Content(json, "application/json");
}
...
[HttpDelete()]
public async Task<ActionResult> ListCacheDelete()
{
await redisCache.KeyDeleteAsync("StockItems");
logger.LogInformation("StockItems list removed");
return this.Ok();
}
}
Like Regular Expressions in .NET, the System.Test.Json object serialisations can be compiled to MSIL code instead of high-level internal instructions. This allows .NET’s just-in-time (JIT) compiler to convert the serialisation to native machine code for higher performance.
public class StockItemListDtoV1
{
public int Id { get; set; }
public string Name { get; set; }
public decimal RecommendedRetailPrice { get; set; }
public decimal TaxRate { get; set; }
}
[JsonSourceGenerationOptions(PropertyNamingPolicy = JsonKnownNamingPolicy.CamelCase)]
[JsonSerializable(typeof(List<StockItemListDtoV1>))]
public partial class StockItemListDtoV1GenerationContext : JsonSerializerContext
{
}
The cost of constructing the Serialiser may be higher, but the cost of performing serialisation with it is much smaller.
[HttpGet]
public async Task<ActionResult<IEnumerable<Model.StockItemListDtoV1>>> Get()
{
var cached = await redisCache.StringGetAsync("StockItems");
if (cached.HasValue)
{
return Content(cached, "application/json");
}
var stockItems = await dbConnection.QueryWithRetryAsync<Model.StockItemListDtoV1>(sql: sqlCommandText, commandType: CommandType.Text);
#if SERIALISER_SOURCE_GENERATION
string json = JsonSerializer.Serialize(stockItems, typeof(List<Model.StockItemListDtoV1>), Model.StockItemListDtoV1GenerationContext.Default);
#else
string json = JsonSerializer.Serialize(stockItems);
#endif
await redisCache.StringSetAsync("StockItems", json, expiry: StockItemListExpiration);
return Content(json, "application/json");
}
I used Telerik Fiddler to empty the cache then load the StockItems list 10 times (more tests would improve the quality of the results). The first trial was with the “conventional” serialiser

The average time for the conventional serialiser was 0.028562 seconds

The average time for the generated version was 0.030546 seconds. But, if the initial compilation step was ignored the average duration dropped to 0.000223 seconds a significant improvement.