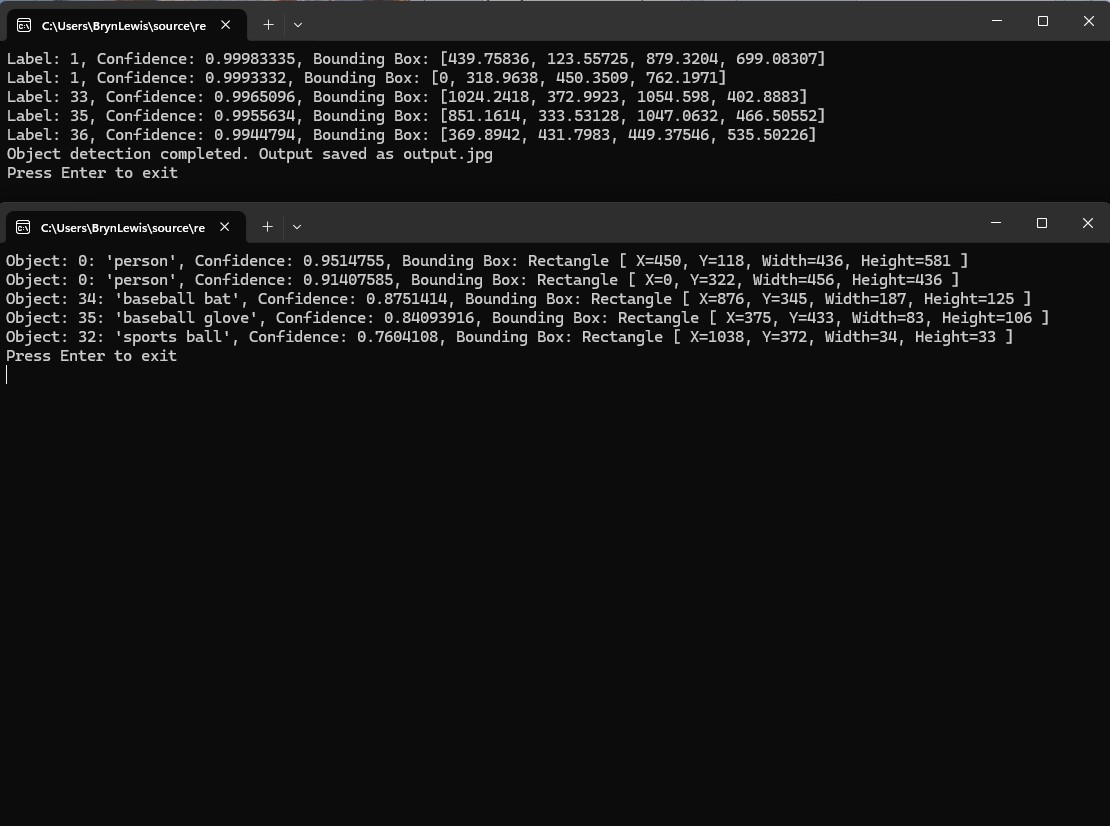
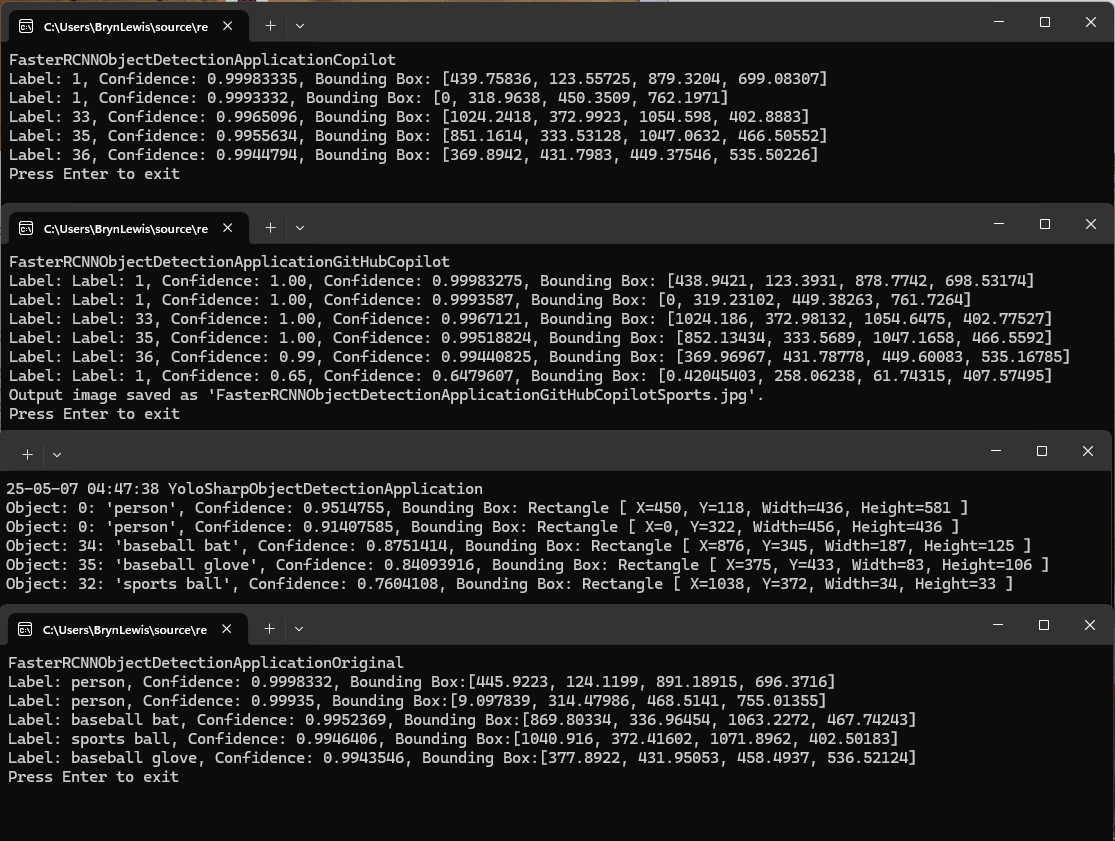
After building Faster R-CCN object detection applications with Copilot and Github Copilot the results when compared with the onnxruntime.ai Object detection with Faster RCNN Deep Learning in C# sample (which hasn’t been updated for years) were slightly different.
The sample image was 640×480 pixels
The FasterRCNNObjectDetectionApplicationGitHubCopilot application scaled image was initially 1056×800 then 1088×800 pixels.
The initial version the dimensions were “rounded down” to the next multiple of 32
// Calculate scale factor to fit within the range while maintaining aspect ratio
float scale = Math.Min((float)maxSize / Math.Max(originalWidth, originalHeight),
(float)minSize / Math.Min(originalWidth, originalHeight));
// Calculate new dimensions
int newWidth = (int)(originalWidth * scale);
int newHeight = (int)(originalHeight * scale);
// Ensure dimensions are divisible by 32
newWidth = (newWidth / divisor) * divisor;
newHeight = (newHeight / divisor) * divisor;

Then for the second version the dimensions were “rounded up” to the next multiple of 32
// Calculate scale factor to fit within the range while maintaining aspect ratio
float scale = Math.Min((float)maxSize / Math.Max(originalWidth, originalHeight),
(float)minSize / Math.Min(originalWidth, originalHeight));
// Calculate new dimensions
int newWidth = (int)(originalWidth * scale);
int newHeight = (int)(originalHeight * scale);
// Ensure dimensions are divisible by 32
newWidth = (int)(Math.Ceiling(newWidth / 32f) * 32f);
newHeight = (int)(Math.Ceiling(newHeight / 32f) * 32f);



The FasterRCNNObjectDetectionApplicationOriginal application scaled the input image to 1066×800

The FasterRCNNObjectDetectionApplicationOriginal application pillar boxed/padded the image to 1088×800 as the DenseTensor was loaded.
using Image<Rgb24> image = Image.Load<Rgb24>(imageFilePath);
Console.WriteLine($"Before x:{image.Width} y:{image.Height}");
// Resize image
float ratio = 800f / Math.Min(image.Width, image.Height);
image.Mutate(x => x.Resize((int)(ratio * image.Width), (int)(ratio * image.Height)));
Console.WriteLine($"After x:{image.Width} y:{image.Height}");
// Preprocess image
var paddedHeight = (int)(Math.Ceiling(image.Height / 32f) * 32f);
var paddedWidth = (int)(Math.Ceiling(image.Width / 32f) * 32f);
Console.WriteLine($"Padded x:{paddedWidth} y:{paddedHeight}");
Tensor<float> input = new DenseTensor<float>(new[] { 3, paddedHeight, paddedWidth });
var mean = new[] { 102.9801f, 115.9465f, 122.7717f };
image.ProcessPixelRows(accessor =>
{
for (int y = paddedHeight - accessor.Height; y < accessor.Height; y++)
{
Span<Rgb24> pixelSpan = accessor.GetRowSpan(y);
for (int x = paddedWidth - accessor.Width; x < accessor.Width; x++)
{
input[0, y, x] = pixelSpan[x].B - mean[0];
input[1, y, x] = pixelSpan[x].G - mean[1];
input[2, y, x] = pixelSpan[x].R - mean[2];
}
}
});


I think the three different implementations of the preprocessing steps and the graphics libraries used probably caused the differences in the results. The way an image is “resized” by System.Graphics.Common vs. ImageSharp(resampled, cropped and centered or padded and pillar boxed) could make a significant difference to the results.