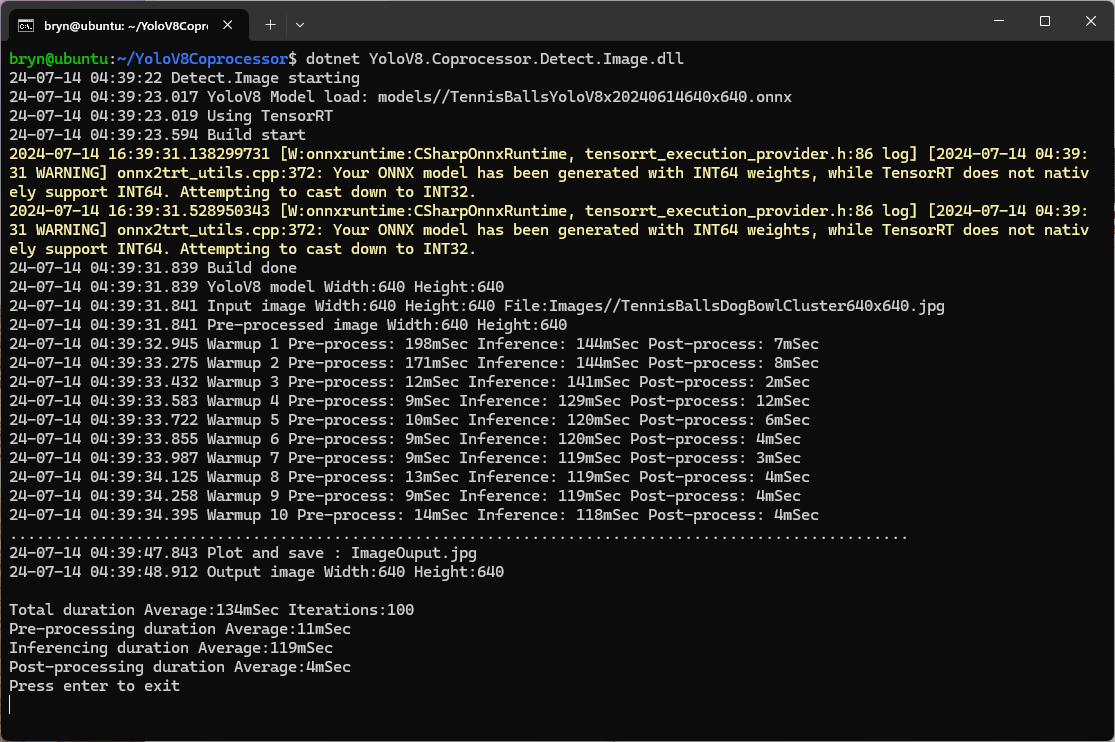
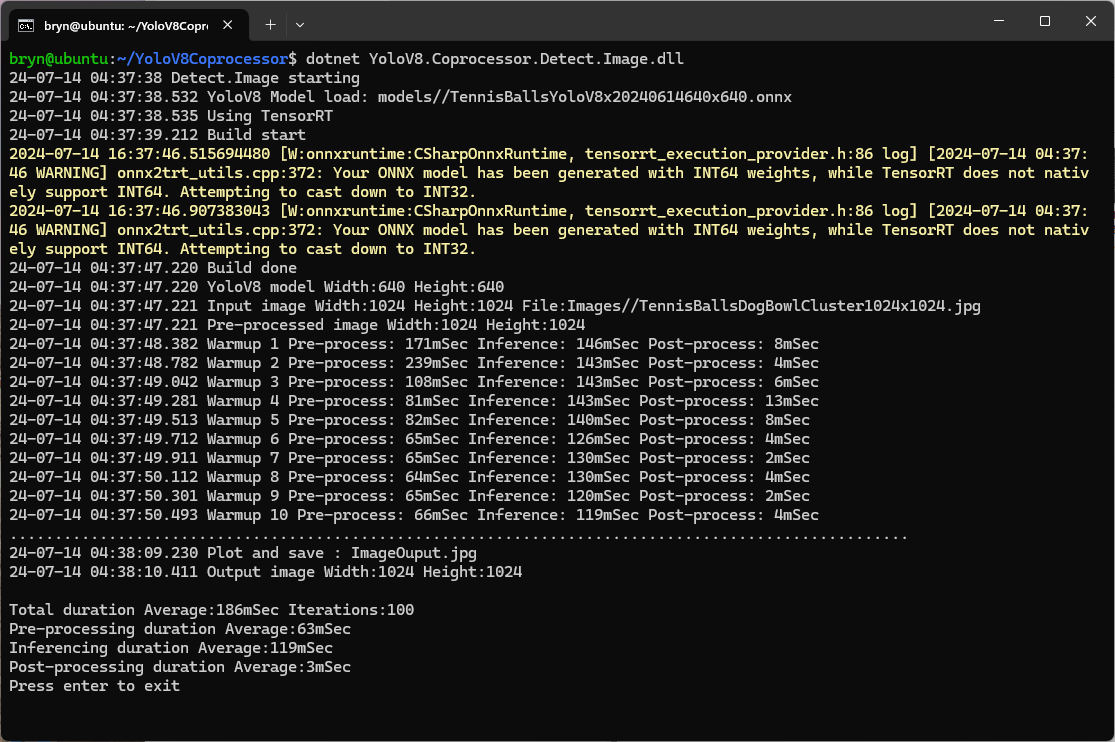
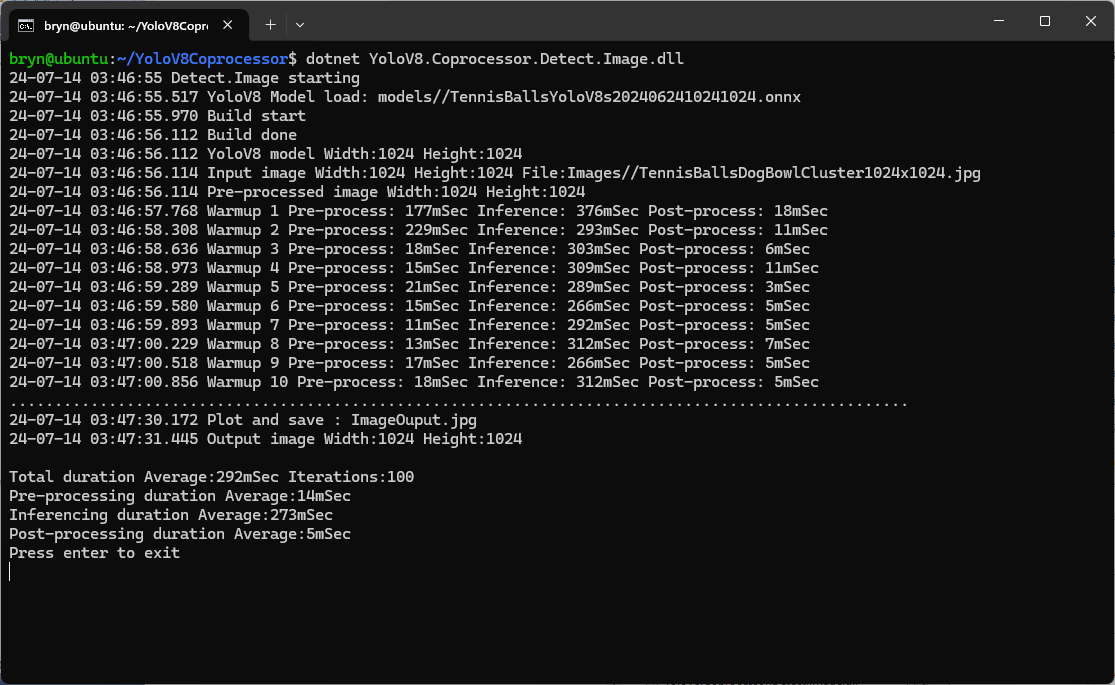
The Seeedstudio reComputer J3011 has two processors an ARM64 CPU and an Nividia Jetson Orin 8G. To speed up TensorRT inferencing I built an Open Neural Network Exchange(ONNX) TensorRT Execution Provider. After updating the code to add a “warm-up” and tracking of average pre-processing, inferencing & post-processing durations I did a series of CPU & GPU performance tests.
The testing consisted of permutations of three models TennisBallsYoloV8s20240618640×640.onnx, TennisBallsYoloV8s2024062410241024.onnx & TennisBallsYoloV8x20240614640×640 (limited testing as slow) and three images TennisBallsLandscape640x640.jpg, TennisBallsLandscape1024x1024.jpg & TennisBallsLandscape3072x4080.jpg.
Executive Summary
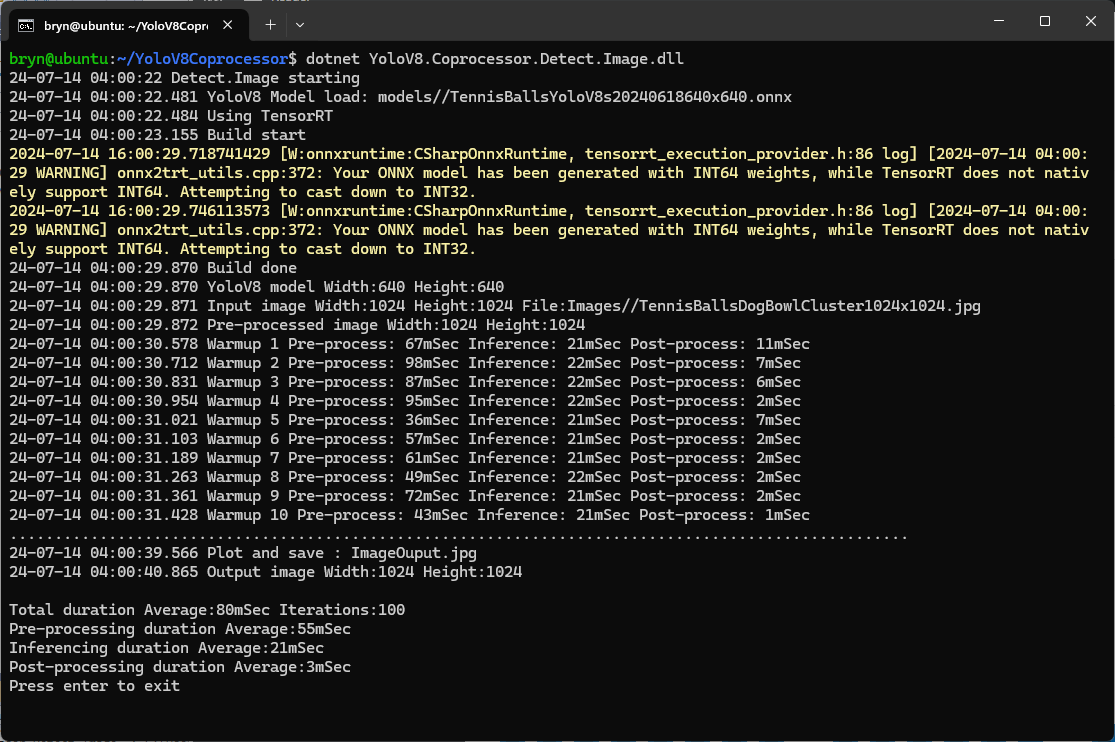
As expected, inferencing with a TensorRT 640×640 model and a 640×640 image was fastest, 9mSec pre-processing, 21mSec inferencing, then 4mSec post-processing.
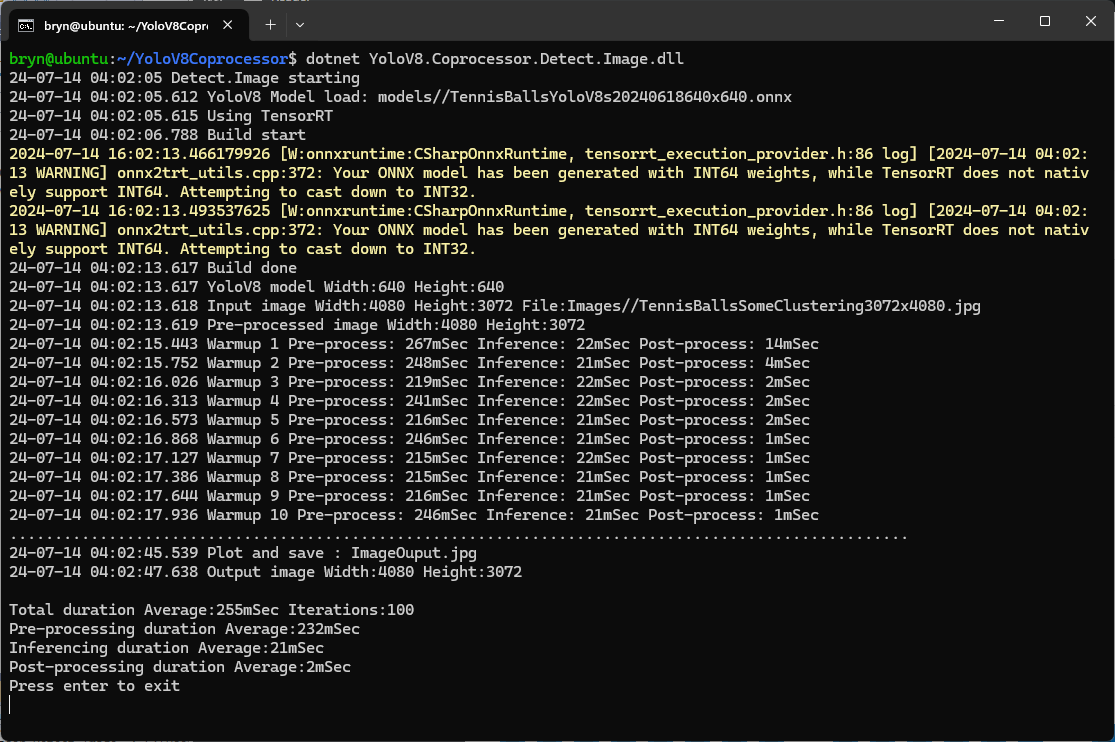
If the image had to be scaled with SixLabors.ImageSharp this significantly increased the preprocessing (and overall) time.
CPU Inferencing
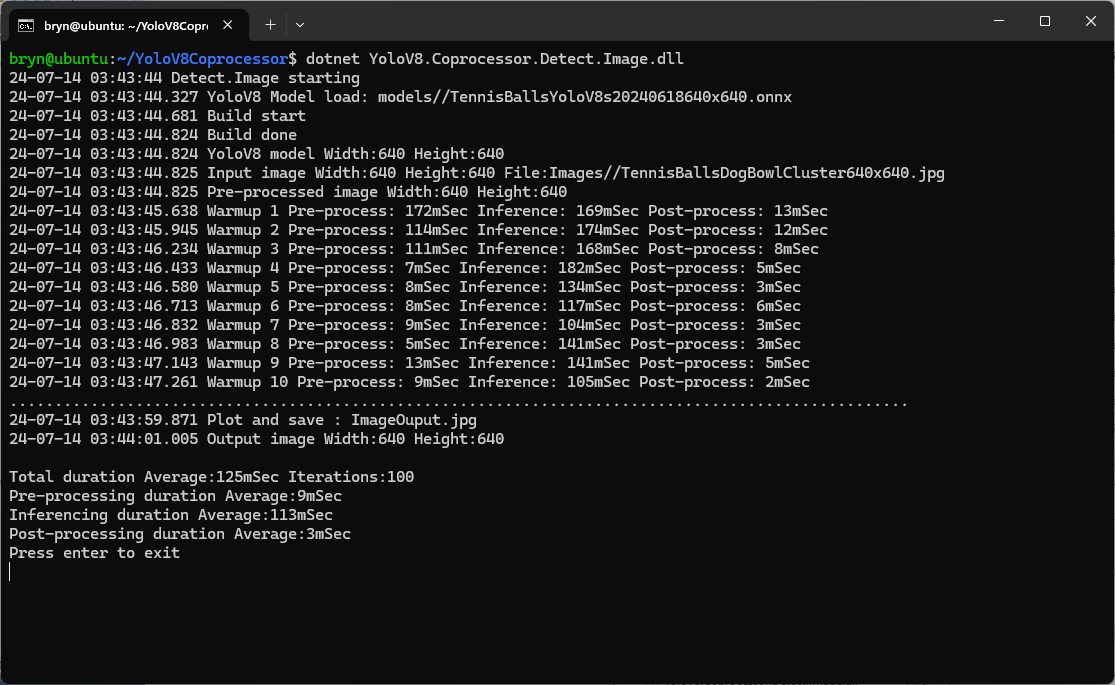

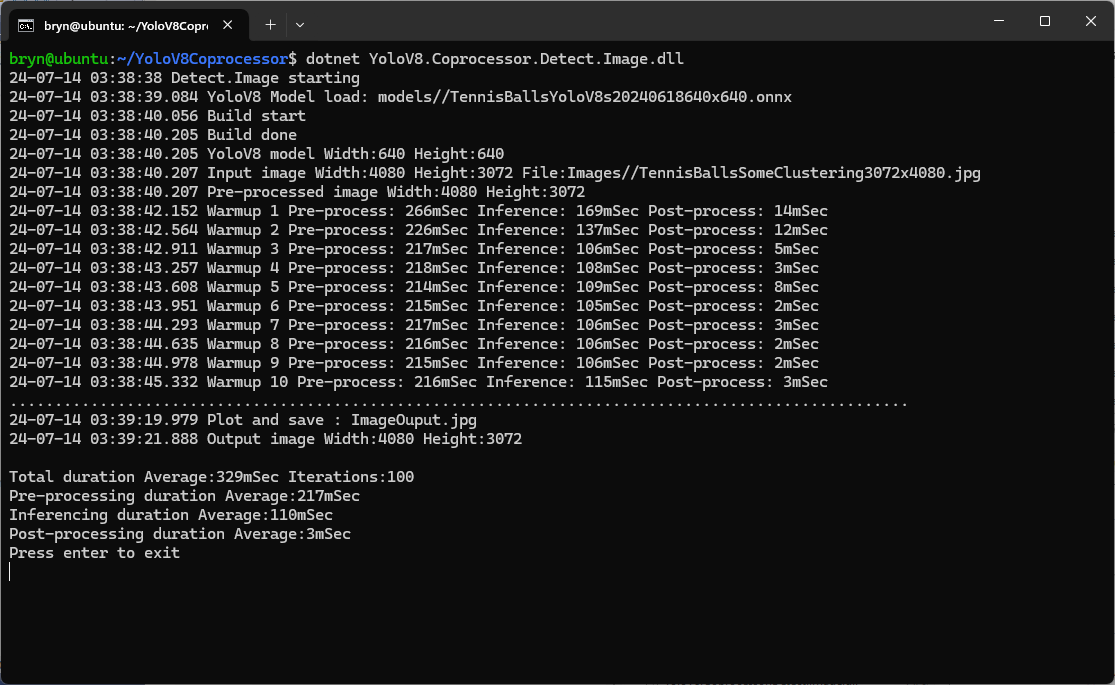


GPU TensorRT Small model Inferencing

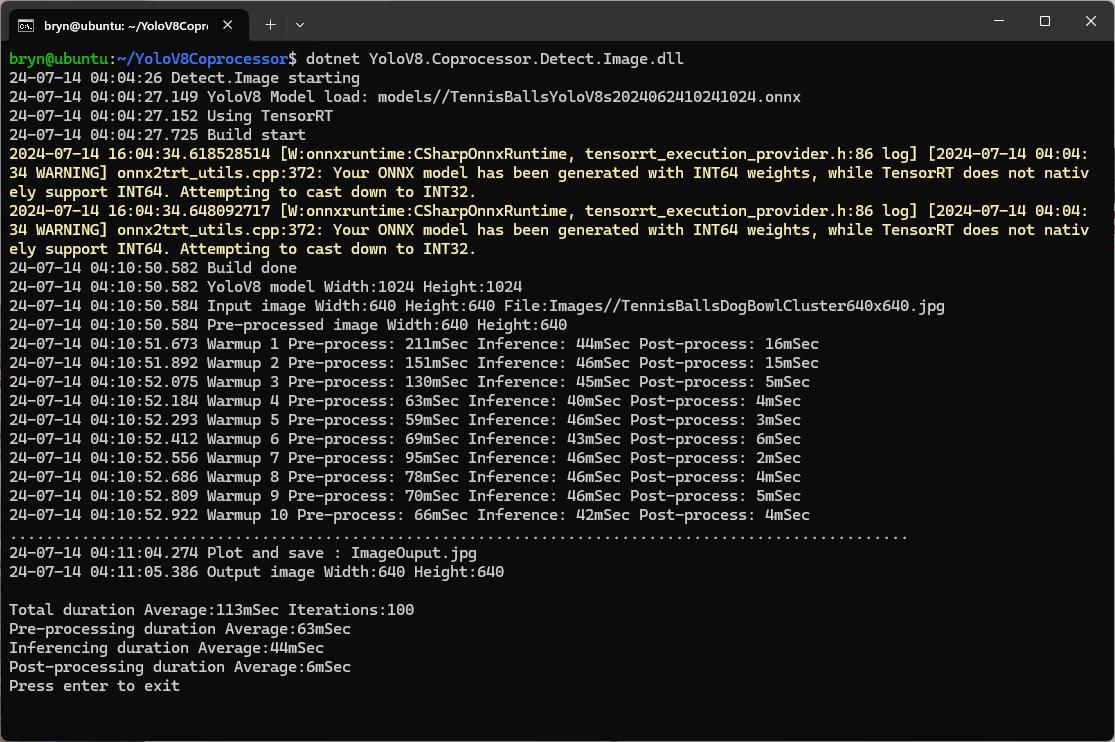


GPU TensorRT Large model Inferencing