The Seeedstudio reComputer J3011 has two processors an ARM64 CPU and an Nvidia Jetson Orin 8G which can be used for inferencing with the Open Neural Network Exchange(ONNX)Runtime.
Story of Fail
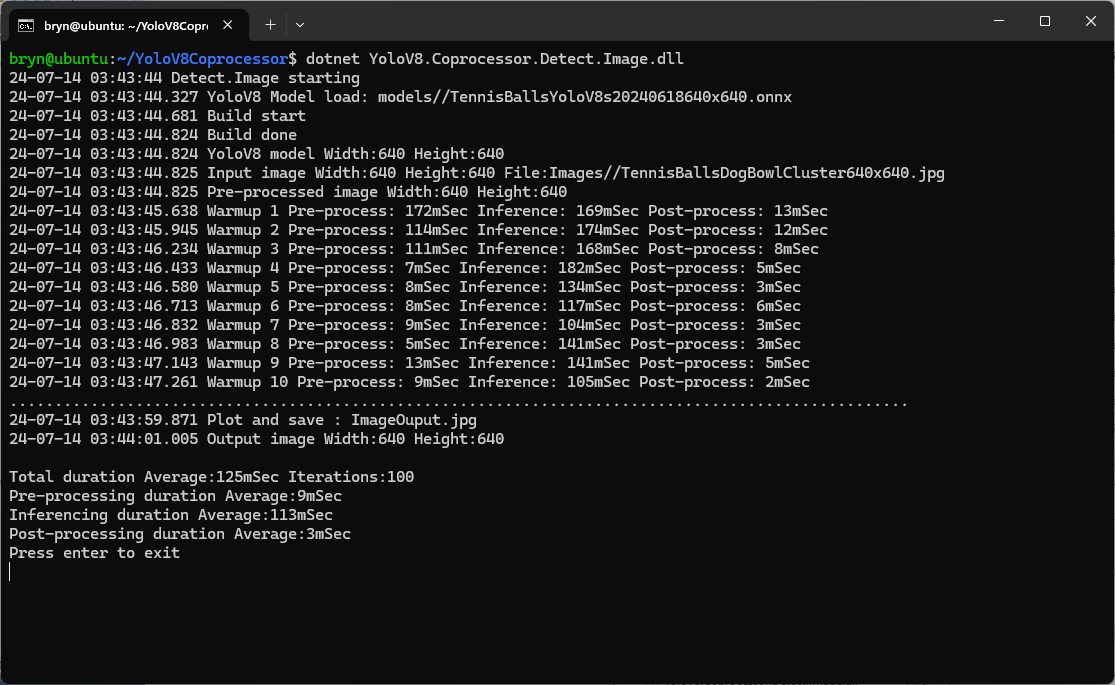
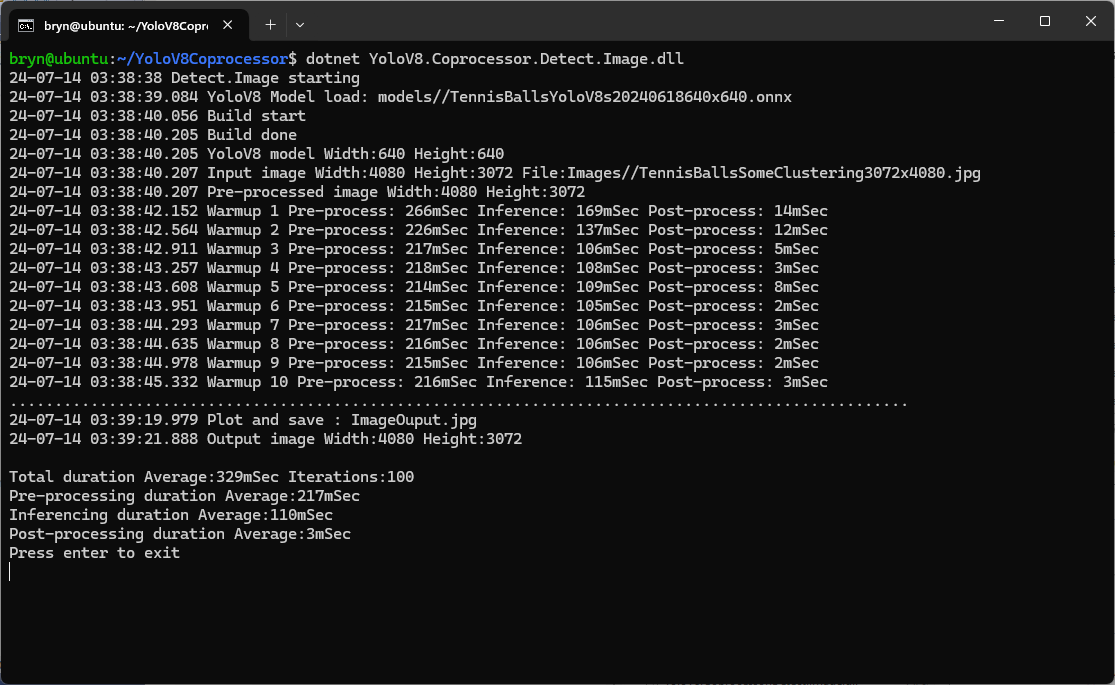
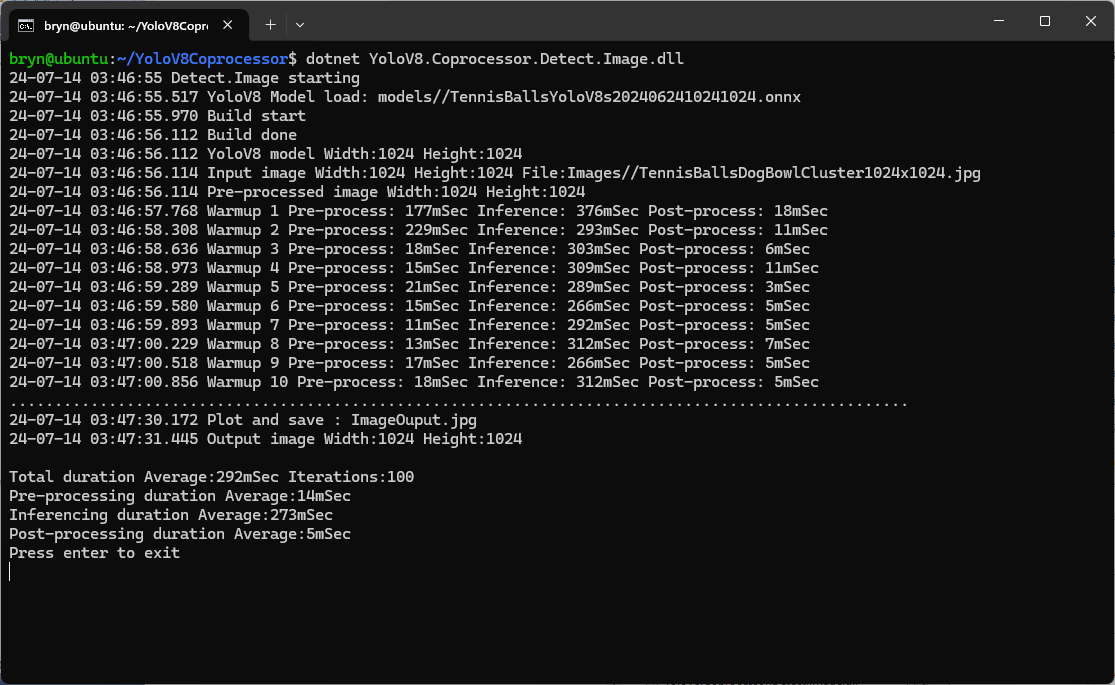
Inferencing worked first time on the ARM64 CPU because the required runtime is included in the Microsoft.ML.OnnxRuntime NuGet


Inferencing failed on the Nividia Jetson Orin 8G because the CUDA Execution provider and TensorRT Execution Provider for the ONNXRuntime were not included in the Microsoft.ML.OnnxRuntime.GPU.Linux NuGet.

There were Linux x64 and Windows x64 versions of the ONNXRuntime library included in the Microsoft.ML.OnnxRuntime.Gpu NuGet

Desperately Seeking libonnxruntime.so
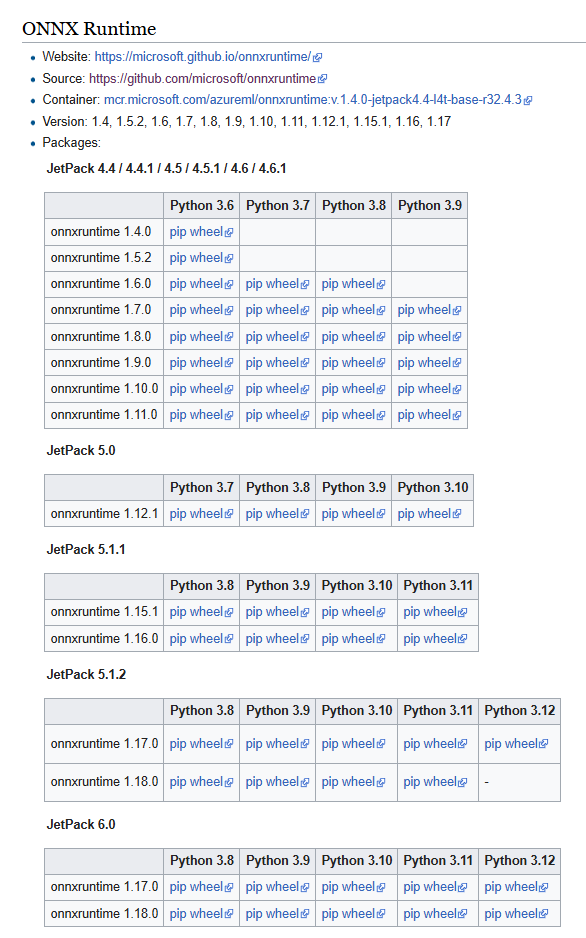
The Nvidia ONNX runtime site had pip wheel files for the different versions of Python and the Open Neural Network Exchange(ONNX)Runtime.

The onnxruntime_gpu-1.18.0-cp312-cp312-linux_aarch64.whl matched the version of the ONNXRuntime I needed and version of Python on the device..
When the pip wheel file was renamed onnxruntime_gpu-1.18.0-cp312-cp312-linux_aarch64.zip it could be opened, but there wasn’t a libonnruntime.so.

Building the TensorRT & CUDA Execution Providers
The ONNXRuntime build has to be done on Nividia Jetson Orin so after installing all the necessary prerequisites the first attempt failed.
bryn@ubuntu:~/onnxruntime/onnxruntime$ ./build.sh --config Release --update --build --build_wheel \
--use_tensorrt --cuda_home /usr/local/cuda --cudnn_home /usr/lib/aarch64-linux-gnu \
--tensorrt_home /usr/lib/aarch64-linux-gnu

When in high power mode more cores are used but this consumes more resource when building the ONNXRuntime. To limit resource utilisation --parallel2 was added the command line because the compile process was having “out of memory” failures.
bryn@ubuntu:~/onnxruntime/onnxruntime$ ./build.sh --config Release --update --build --parallel 2 --build_wheel \
--use_tensorrt --cuda_home /usr/local/cuda --cudnn_home /usr/lib/aarch64-linux-gnu \
--tensorrt_home /usr/lib/aarch64-linux-gnu

There were some compiler warnings but they appear to be benign.

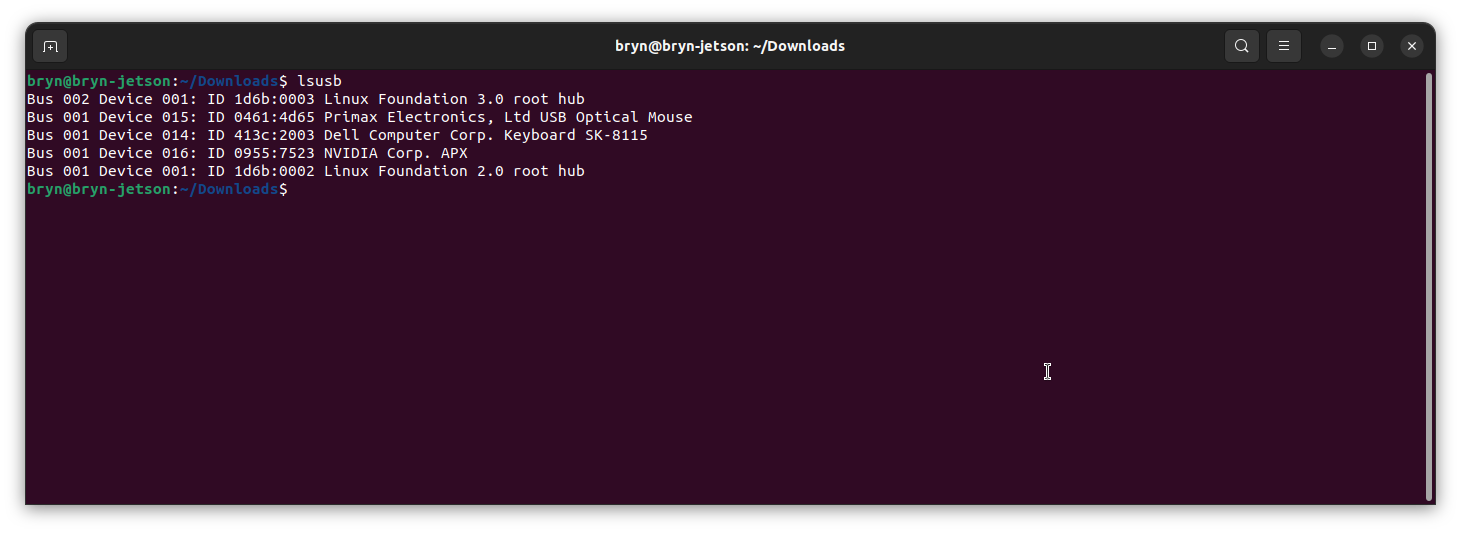
First attempt at running the application failed because libonnxruntime.so was missing so –build_shared_lib was added to the command line
2024-06-10 18:21:58,480 build [INFO] - Build complete
bryn@ubuntu:~/onnxruntime/onnxruntime$ ./build.sh --config Release --update --build --parallel 2 --build_wheel --use_tensorrt --cuda_home /usr/local/cuda --cudnn_home /usr/lib/aarch64-linux-gnu --tensorrt_home /usr/lib/aarch64-linux-gnu --build_shared_lib

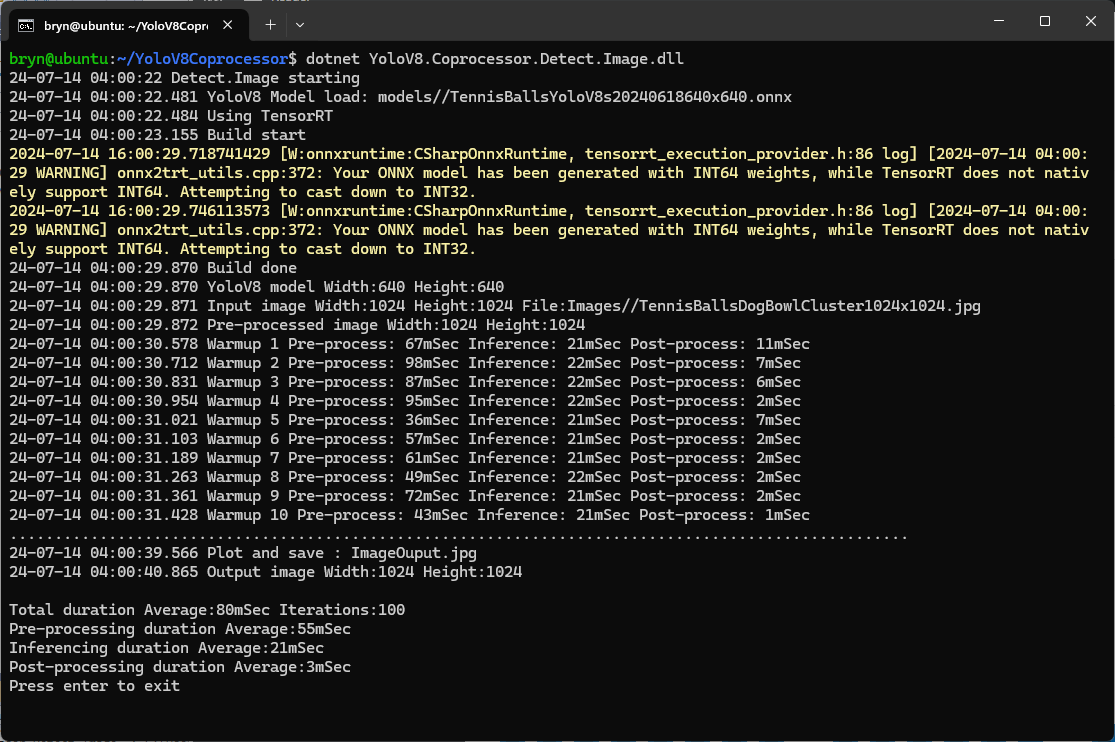
When the build completed the files were copied to the runtime folder of the program.

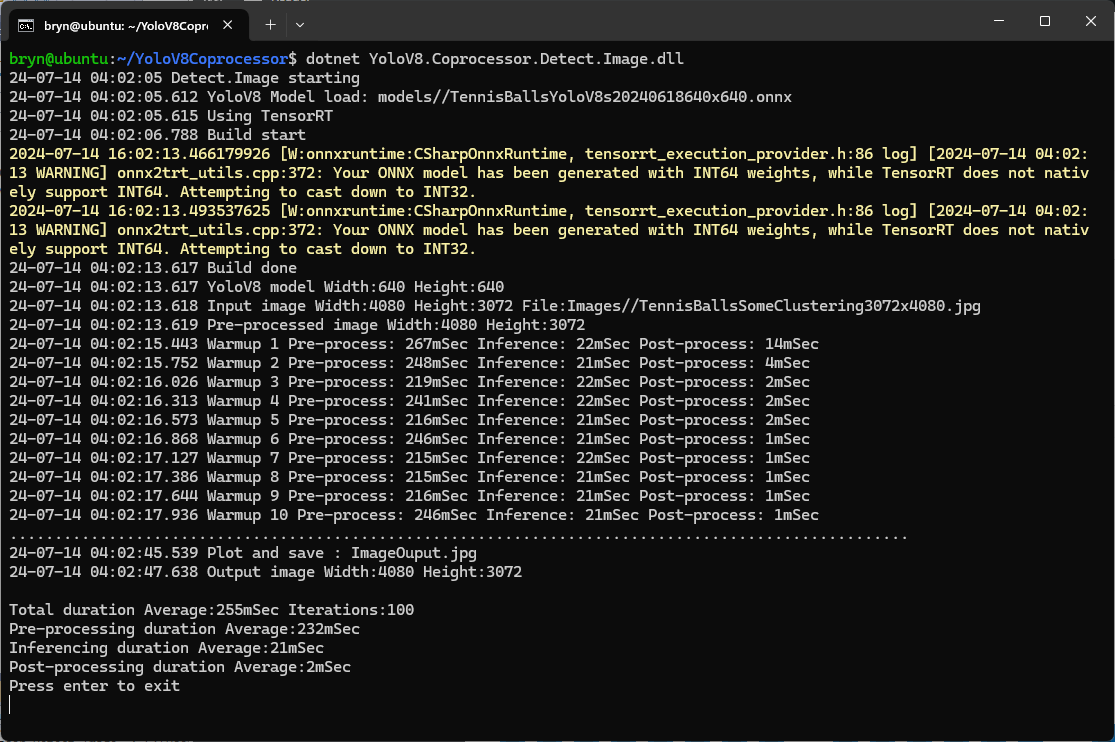
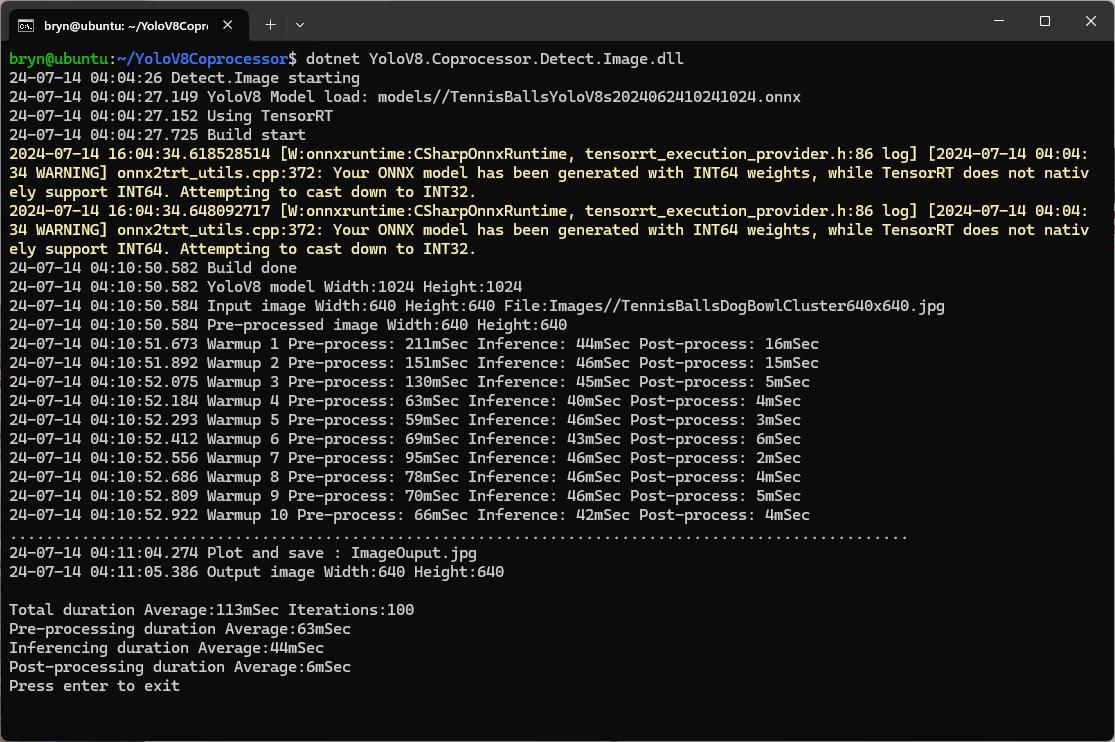
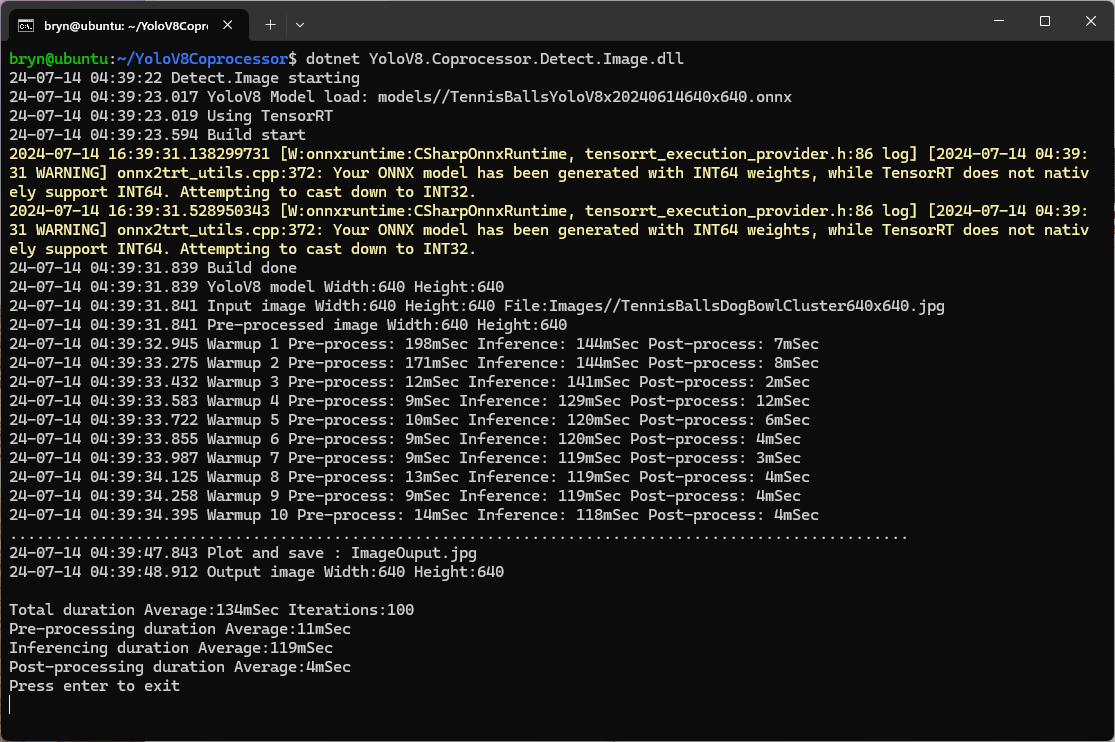
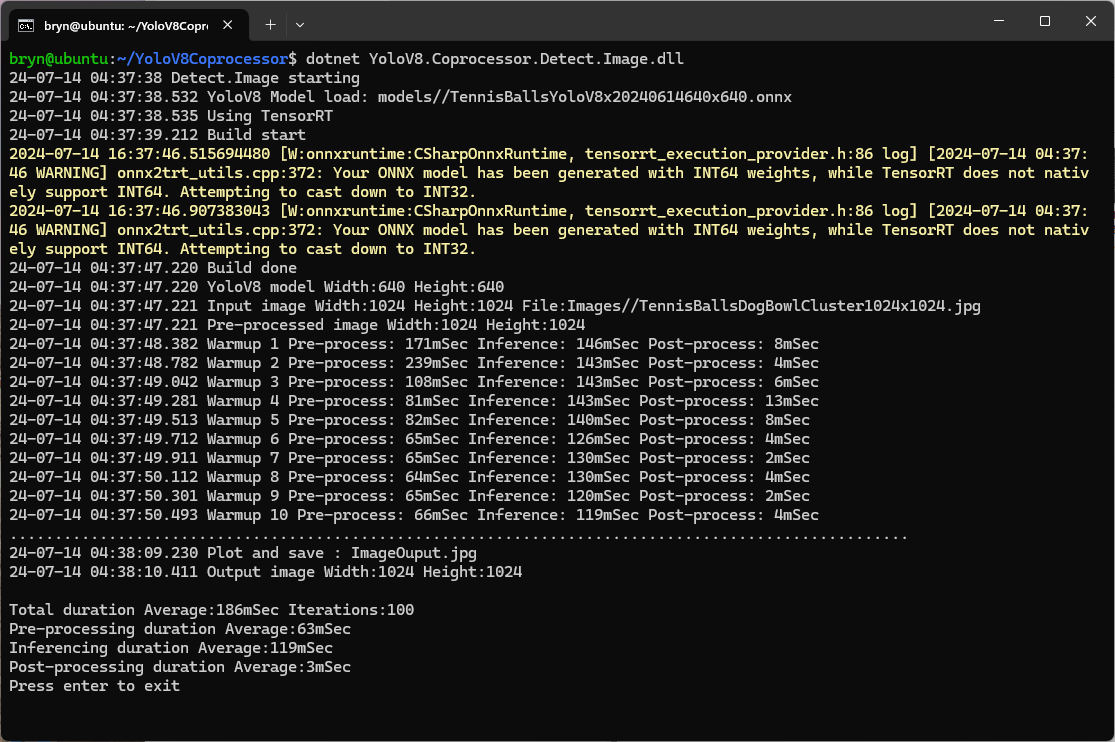
The application could then be configured to use the TensorRT Execution Provider.

Getting CUDA and TensorRT working on the Nvidia Jetson Orin 8G took much longer than I expected, with many dead ends and device factory resets before the process was repeatable.